2021暑假已过大半,我的大二也即将结束,大二与大三似乎过度得很仓促。不太愿意承认自己马上就要大三了,好像什么都还没做这个夏天又要过去了,好像什么都没做就马上要走出大学的校门了。
这个暑假事情是比较多的,要准备9月初数模国赛,大创项目也要准备开题路演,而我又在实习。本来计划这个暑假初步完成大创的前端初稿,沉淀一下前端知识,得推一推了。马上开学而数模计划学习进度才刚过半,距离9月10号没剩几天了,得抓紧了✊练了一套19年国赛D题,本来以为会主要把时间花在模型训练,没想到的是大半时间都卡在数据清洗😅,这道题断断续续给我做了半个月😅下面主要写的是XGBoost模型建立的代码,以及参数调整方法,本项目所用到的所有代码都已上传到我的Github,包括数据清洗,欢迎学习交流。
正文分割线
在学习集成算法之前,我有学过一点神经网络和智能算法(模拟退火,遗传算法)我发现其实这些算法是有点共性的,智能算法像是神经网络的祖先,里面提到的梯度下降等各种概念特别是遗传算法和非常神经网络神似。
集成学习主要分为Bagging,Boosting,前者代表为随机森林,后者为XGBoost、GBDT
按照我的理解XGBoost就像是用多个小而简单的多项式相加代换一个复杂整体的表达式,就像高数里面最令人头疼泰勒展开式一样。这里算法细节不在具体解释,下面上代码:
代码展示
导包基操:
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
# 导入数据
from xgboost import plot_importance
data = pd.read_excel('合并.xls')
data.head()
# 切分数据集
feas = data.columns
feas_var = feas[0:11] # 多维输入变量
feas_lab = feas[12] # 输出变量
X = data[feas_var]
Y = data[feas_lab]
# 切分训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(X, Y, test_size=0.3, random_state=90)
模型训练:
# 训练模型
xgb_model = xgb.XGBRegressor(n_estimators=1000, random_state=50, verbosity=1, max_depth=15, min_child_weight=4, gamma=0.6)
xgb_model.fit(x_train, y_train, eval_metric='mae', eval_set=[(x_valid, y_valid)], early_stopping_rounds=100)
模型评价:
# 模型评价
from sklearn.metrics import mean_absolute_error, mean_squared_error, accuracy_score
xgb_pred = xgb_model.predict(x_valid)
print(np.corrcoef(xgb_pred, y_valid)[0, 1] ** 2) # 相关系数
print(mean_squared_error(xgb_pred, y_valid)) #均方误差
print(mean_absolute_error(xgb_pred, y_valid)) #平均绝对误差
# 准确率
# accuracy = accuracy_score(y_valid,xgb_pred)
# print('accuarcy:%.2f%%'%(accuracy*100))
# 显示重要特征
plot_importance(xgb_model)
plt.show()
结果展示:
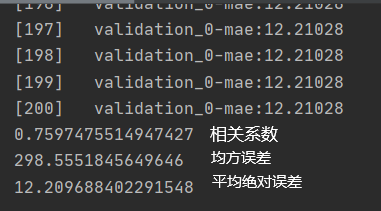
相关系数0.75还算可以吧
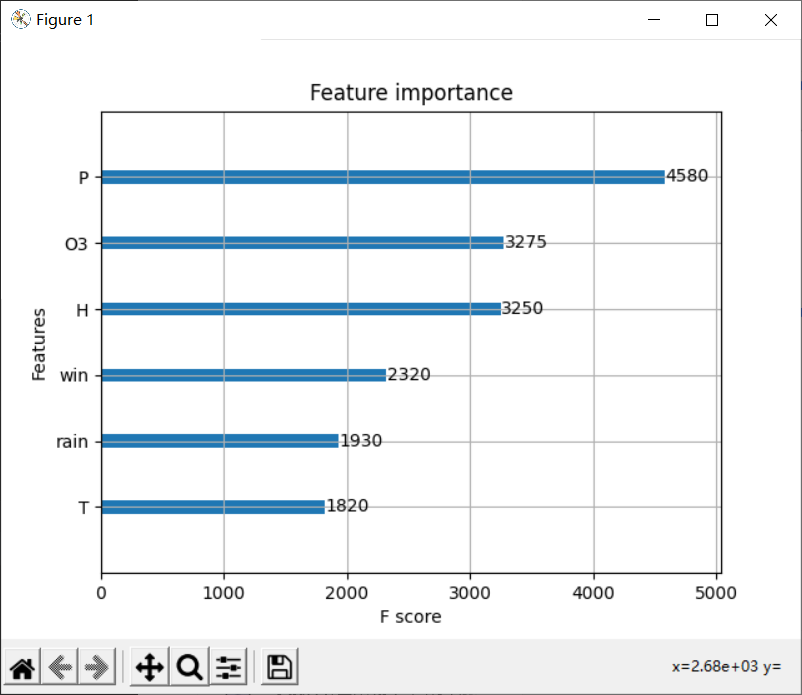
很明显压强对于自建点检测值偏差影响较大
参数调整
任何模型训练最头疼的就是参数调整了吧,之前写得神经网络调参也是我最头疼的一块,神经网络参数改动一点点效果也真的改动亿点点,不敢乱调神经网络,还好XGBoost比神经网络好调参,我在网上找到了一些XGBoost调参方法收藏一下。


一般先调生成树的个数,一般树个数越多,效果越好,但是树的增加会是代码运行非常缓慢,存在边际效益递减,树的的个数越多,搭配较小的学习率更好。



