面试前重点看:
- 浏览器渲染原理(栅格化、分块)++
- V8引擎原理++
- 前端渲染历程(ssr、csr、预渲染、异构SSR、esr原理)
- 如何封装一个组件
- 虚拟滚动列表原理
- 还知道哪些性能优化方案
- 移动端适配
- diff算法原理
手写reduce、all、节流不太熟
计划放前面
12/19
考虑增加自定义指令:实现防抖节流,按钮级别权限校验,输入框自动聚焦
11.18 看柯里化和浏览器渲染过程 包括位图栅格化..
叨叨姐字节面经常规深度面经:https://www.nowcoder.com/discuss/954312
ssr、ssg、Faas
11.8
考虑是否增加手写虚拟滚动列表
- margin 穿透和重叠
- BFC、IFC、FFC、GFC
- 重构ssr、异构ssr、流式渲染、孤岛渲染
- intersectionAPI 没有占用js线程?
- 瀑布流式组件开发
- cros
- postman存在跨域?
- netlink
- 离屏渲染(***双缓存区***?) 浏览器刷新频率怎么刷新?双缓存原理
- canvas——cluster
- https://www.cnblogs.com/powertoolsteam/p/15213573.html
- VUE源码设计顶层视角
- 双缓存区
11.4看到 treeShaking和…..compone区别
11.2 写到实习经历的encodeuri // 关键渲染路径
11.1
1、先把简历上的八股重新整理一遍,保证简历上的八股都能答好——然后可以慢慢投小公司简历。
2、过一遍之后然后再上牛客上看一下新的八股查缺补漏。
3、切记东看看细看看,导致焦虑内耗啥也没复习好。
10.21
1、以面试为中心背题
10.20/10.21
- 1、LRU算法
- 2、各种排序时间空间复杂度 手写
- 3、UDP原理
- 4、CDN原理
- 5、OSI 7层模型
缓存策略的头部看一下
http3.0补充一下
http 告一段落(后面可以看一下http状态码)
- 简历补充:虚拟滚动列表的实现原理、还有vue预渲染的插件(prerender-sap)原理准备一下
简历上的知识点更改一下,一定要自己非常有把握的
b站山月老师视频常看一下
开启新第一轮计划——基础八股查缺补漏(中小厂offer保底)
把牛客上所有的面试题过一遍。
开启第二轮计划——复习数据结构!(大厂必考)
面经收集
大厂汇总:https://www.nowcoder.com/discuss/1062791
汇总:https://www.nowcoder.com/discuss/713375
超全汇总:https://www.yuque.com/boyyang/buosw0/idgxnb
机械大猛子:https://www.nowcoder.com/discuss/828616
用友:https://www.nowcoder.com/discuss/738797 (用友面经,建议全部看过一遍nowcode上的)
内推收集
吉比特&雷霆:https://www.nowcoder.com/discuss/1025341
秋招&实习汇总: https://mp.weixin.qq.com/s/HMI62gGxC2ReTPfpvV8ixA
汇总:https://docs.qq.com/sheet/DQ3lCc0ZEV25pV0V1?tab=BB08J2
自我介绍
面试官您好,我叫陈勇强,来自天津商业大学信息工程学院电子商务专业,我面试的岗位是前端开发岗位。
我将从校园经历、实习经历、项目经历3个方面进行自我介绍。
校园经历方面:我从大一下学期开始加入了维护学校官网的技术社团,从那时候开始慢慢接触前端了。在校园里各方面也算是个积极分子,当过班干,参加过许多比赛,也有一点收获,拿过一个国奖,三个省奖,还发过一篇SCI,是关于机器学习混合优化算法改进与应用的。
实习经历方面:有过两段实习经历,一个是大二暑假,当时主要负责的是北京林业大学园林学院官网的首页制作,根据设计稿精准还原页面视图;第二个就是在大三的暑假在联想云参与了两个项目需求周期。目前主要的技术栈是vue2、vue3学过一些。
项目经历方面:做过三个项目,一个是帮我们学院党建办公开发的智慧党建系统,一个文章后台管理项目,还有一个仿喜马拉雅的微信小程序。
首先一个前端项目最基本的要素就是业务,基础功能得实现了:
在项目里我实现了
三个项目都实现了登录功能——>我是用的技术的Token认证技术相比cookies、session,防范了csrf (跨站请求伪造) 攻击。(提问点:cookies、session、token、jwt认证机制区别和好处?CSRF攻击?)
基础功能包括,数据表格展示,表单提交,文件上传与导出,搜索框历史功能。
移动端适配(提问点:多种适配方案优缺点,避免使用100VH)
角色权限管理
其次,前端作为直接与用户接触的一端,也承载了交互体验的功能,我们需要以用户的角度去考虑功能交互体验,同时可以在一定程度上弥补性能方面的不足。
在交互方面:
通过骨架屏让使得去提升交互
使用组件的动画,提升交互细节
通过nprogress这个小进度条提升交互感
通过betterScroll使得页面滑动变得更加的丝滑
最后一个是性能优化方面:
我通过:
我用prerender-spa-plugin做了预渲染,提高网站的SEO,以及将首屏加载速度提升了500ms
通过 vue-virtual-scroller 插件进行长列表渲染优化,有效提高网页加载速度。
通过路由懒加载实现首屏优化、按需加载
通过 CDN 引入外部资源来减少首屏渲染时间
通过约束自身代码规范,减少对dom操作,减少重绘和重排;及时对闭包中的对象进行清除。
前端作为服务端和用户沟通的桥梁,我认为在完成基本业务的基础上,不仅要从用户的角度思考交互,还要在一定程度上辅助服务端分担性能压力。
综合以上业务、交互、性能优化三个方面,就是我在项目中职责,也是我认为前端的职责所在。
自我介绍中面试官可能的切入点
- 实习期间做过什么稍微复杂的需求
- token认证技术,csrf
- 单点登录你是如何实现的,还有什么方案—cookies、认证中心
- 搜索框历史怎么实现?—数组序列化(JSON.stringfy)后存入localStorage,在页面destroyed是存入localStorage
- 移动端适配 ->视口->mata标签->常规方案
- 骨架屏如何配,原理
- 预渲染原理,其他解决方案
- 性能指标数据怎么查看?还知道哪些性能指标
- 虚拟滚动长列表渲染的原理
- 路由懒加载原理
- 手写防抖、节流
实习经历
场景题(实习期间有没有做过什么复杂的需求) + 实践
1、父子组件生命周期问题
场景:父组件在 mounted 发送异步请求获取数据,子组件在mounted获取父组件请求的数据,无法获取。
自我探索与思考:然后我就猜是不是请求的时间比钩子函数间触发的时间长了,我就给mounted 这个函数加上了 async await,发现还是获取不到。我就猜想是不是会不会跟父子组件生命有关,就自己写了个小demo测试了一下,结果发现还真是这个原因。
原因:父子组件生命周期顺序问题。
父beforeCreate -> 父created -> 父beforeMount -> 子beforeCreate -> 子created -> 子beforeMount -> 子mounted -> 父mounted->
父beforeUpdate->子beforeUpdate->子updated->父updated->父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
子组件的 mounted 先触发,再到父组件的mounted所以获取不到。
(引申)1、那么获取请求一般写在哪里?
created: 如果将 API 请求放到 created 里的话,实际上是这样一个过程:

也就是说,再发送 API 请求以后,就会产生 2 个分支,代码逻辑比较混乱。
mounted:再来分析 mounted 里的情况
可以看到整个逻辑是这样的:
created => mounted => mounte组件首次渲染 => API请求 => 获取到数据 => update组件重新渲染
可以看到,没有分支,只有一个流程。
再来分析 mounted 里的情况
如果在mounted钩子函数中请求数据可能导致页面闪屏问题
(引申)2、组件生命周期
2、右键复制分享路径
场景:右键点击分享,复制分享链接,连接粘贴到粘贴板,在地址栏粘贴跳转
右键菜单(mixin混入,增加配置项)——>点击复制连接(发送请求获取分享链接)复制到剪切板——>链接粘贴至 url 跳转 ——>重定向到功能页,发送请求根据短链解析目的链接地址
3、首页进入
场景:
林乐文 10-8 16:47:29
我记得之前就是排查 正常接口报401都回登录页 看接口报错一堆401但是没触发回登录,后来查那个接口查promise.all发现接口报错没反应
林乐文 10-8 16:48:12
中间好像也走了些弯路 以为是隐私协议弹窗写太早了 发现注了也没用
4、实习联调的时候有没遇到过跨域,怎么解决的?
vue框架的跨域
通过 vue-cli脚手架搭建项目,可以通过 webpack设立一个本地服务器作为请求的代理对象,通过该服务器转发请求至目标服务器,得到结果后再转发给前端。但是在最终项目发布上线时,如果 web应用和接口服务器不在一起仍会产生跨域问题。解决方法是,可以在vue.config.js文件中新增以下代码: devServer
module.exprots = {
devServer: {
host: '127.0.0.1', // 本地地址
port: 8084, // 端口号
open: true, // 配置项目在启动时自动在浏览器打开
proxy: {
'/api' : { // '/api'是代理标识,一般是每个接口前的相同部分
target: "http://xxx.xxx.xx.xx:8080", // 请求地址,一般是服务器地址
changeOrigin: true, // 是否进行跨域
pathRewrite: { // pathRewrite的作用是把请求接口中的 '/api'替换掉,一般是替换为空""
'^/api':""
}
}
}
}
}
公司正真开发写法,在.env文件里配置proxyTarget,在vue.config.js中配置 判断是否使用当前代理。

5、解决文件路径包含特殊字符无法访问
场景:1、新建文件夹名称包含特殊字符 —> 2、点进新建文件夹报错 —> 3、控制台参数错误
1、路由路径中 %、# 等特殊字符。
- 当URL路径参数中存在%时会报错URI malformed;当 # 作为路由参数时会被识别为用于分隔 URI 组件的标点符号
- 原因:vue-router内部使用decodeURIcomponent转码,通过%进行解析,如果字符串中存在%,则会出现问题
- 决方式:将路径的 % 使用转义字符 %25表示,将 # 用转义字符 %23 表示
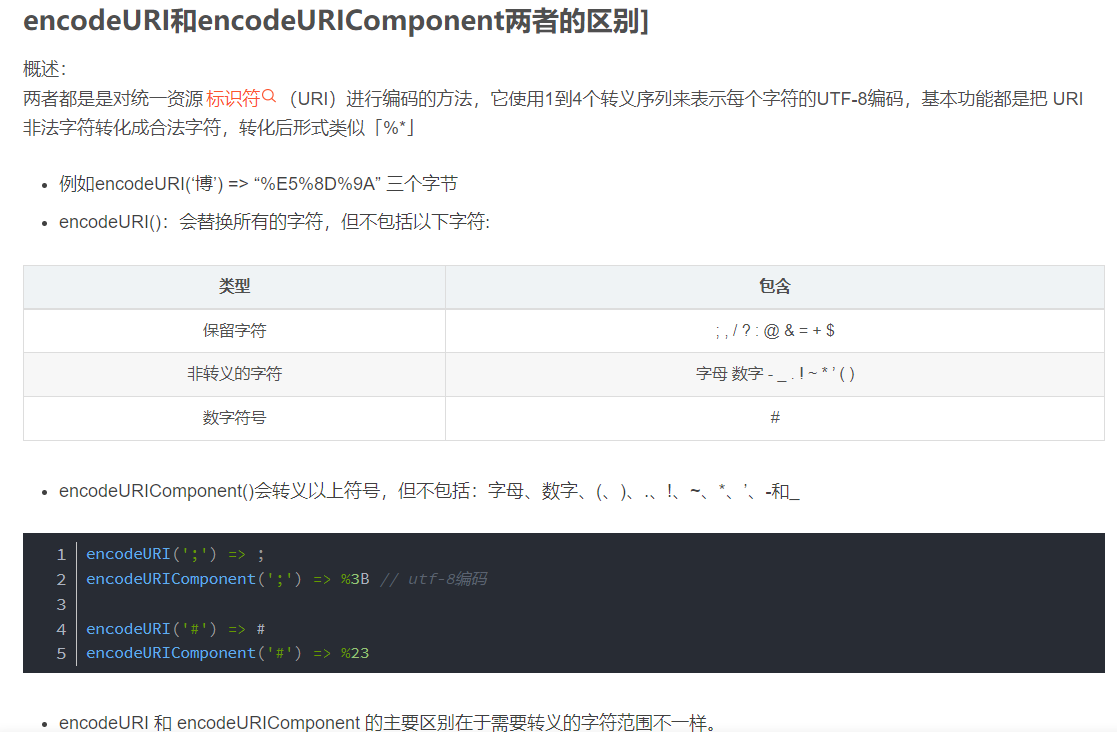
2、JavaScript的四个URL编码/解码方法
encodeURI
encodeURI 是对整个 URI 进行转义,将 URI 中的非法字符转换为合法字符,所以对于一些在 URI 中有特殊意义的字符不会进行转义。
将元字符和语义字符之外的字符都进行转义,一般用于知道该URL只用于完整的URL时使用、
- encodeURIComponent
将除了语义字符之外的字符进行转义,包括元字符,因此,它的参数通常是URL的路径或参数值,而不是整个URL。
encodeURIComponent 是对 URI 的组成部分进行转义,所以一些特殊字符也会得到转义。
- decodeURI
还原转义后的URL,是encodeURI方法的逆运算。
- decodeURIComponent(此方法可以还原被转义的 url)
还原转义后的URL片段。是encodeURIComponent方法的逆运算。
以下字符不会被encodeURIComponent进行编码
- 不会编码 ASCII 字母和数字
- 不会编码 ASCII 标点符号进行编码: - _ . ! ~ * ‘ ( )
- 不会编码用于分隔 URI 组件的标点符号 :;/?:@&=+$,#
- ps:特殊符号需要用 转义序列进行替换
encodeURI 是对整个 URI 进行转义,将 URI 中的非法字符转换为合法字符,所以对于一些在 URI 中有特殊意义的字符不会进行转义。 encodeURIComponent 是对 URI 的组成部分进行转义,所以一些特殊字符也会得到转义。 escape 和 encodeURI 的作用相同,不过它们对于 unicode 编码为 0xff 之外字符的时候会有区别,escape 是直接在字符的 unicode 编码前加上 %u,而 encodeURI 首先会将字符转换为 UTF-8 的格式,再在每个字节前加上 %。
公司解决方案:
export function getMyEncodeURI (path) {
path = encodeURI(path).replace(/&/g, '%26').replace(/#/g, '%23').replace(/\+/g, '%2B')
return path
}
URL 和 URI 的区别?
URI: Uniform Resource Identifier 指的是统一资源标识符
URL: Uniform Resource Location 指的是统一资源定位符
URN: Universal Resource Name 指的是统一资源名称
URI 指的是统一资源标识符,用唯一的标识来确定一个资源,它是一种抽象的定义,也就是说,不管使用什么方法来定义,只要能唯一的标识一个资源,就可以称为 URI。 URL 指的是统一资源定位符,URN 指的是统一资源名称。
URL 和 URN 是 URI 的子集,URL 可以理解为使用地址来标识资源,URN 可以理解为使用名称来标识资源。
详细资料可以参考: 《HTTP 协议中 URI 和 URL 有什么区别?》 《你知道 URL、URI 和 URN 三者之间的区别吗?》 《URI、URL 和 URN 的区别》
开放性思考题
你认为阅读源码对工作有帮助吗
(千万不要说自己没读过源码或者没有用!结合具体场景说)
答:
首先,第一个是能提升对框架使用的熟练度;阅读源码能让我们对框架有深刻的理解,让我们更好的运用它。举个栗子,在初学 vue2 的时候,我很容易犯的一个错误,就是直接通过this.属性 定义一个新的数据,然后就会出现数据无法动态更新的问题,排查半天到网上搜索才知道如果要这样写的话必须要用vue.set()方法才能是数据变成响应式。那么为什么要这样写呢?如果你知道它的响应式原理底层用的是defineproperty(),这个方法是无法动态监听到对象属性的新增和删除,那么你在写代码的时候就会避开这个问题,避免了不必要的排查bug时间,提高工作效率。
第二个,学习到源码书写代码的风格和技巧;如何让代码看起来更简洁干练。比如说它这里用到闭包,变量持久化怎么做的,什么时候释放。还有巧用 &&(与)运算符,三目运算符,一行就能解决的代码,如果自己写的话可能就是笨拙的三行if else。还要在以前在用 vuex-persistedstate 插件给VUEX做持久化的时候,读过它的源码,发现它用的也是 localStorage,不过它还用了一个vuex的API surbcribe() ,如果我自己写的的话可能就是在每个mutation手动存 localStorage看起来不太友好。 surbcribe() API就是学到的好用的写法。
(第三个)为了更好的改造轮子,比如我们公司有一次遇到一个客户,他们那有一个长列表功能反馈用起来很卡,本来计划那个场景下应该渲染的数据最多不会超过100条的,结果他们那超过1000条,我们公司组件库是基于ant design封装的,vue2.0版本的ant中没有对长列表做虚拟滚动,vue3.0版本的底层自动做了虚拟滚动优化,我们就需要把虚拟滚动这个技术封装到vue2.0中。
第三个,学习架构设计模式,设计思想;学习开源大牛们是如何运用设计模式的,然后运用到我们开发的项目中,使我们的项目的模块更易于扩展。
项目性能优化
1、vue-virtual-scroller 长列表渲染优化解决的什么问题?实现原理是什么?
传统的解决方案和问题
传统的解决方案是是用数据懒加载 + 节流
存在问题:一开始挺顺畅,但是到后面随着数据的加载越来越多,dom结构变得越来越多,加载新数据的时候就会变得卡顿,因为插入dom元素会造成重排和重绘。
最佳解决方案:虚拟滚动列表
实现原理:
设置一个固定高度的可视窗口,在页面上只渲染可视窗口内的数据。每个item有一个固定的高度,可是窗口内渲染的数据条数是固定的。通过监听滚动事件,获取滚动上卷的高度,scrolltop / 每个item 的高度 = 滚过去的条数 = startIndex ——> 使用slice方法根据index切分数据进行渲染

此处为语雀内容卡片,点击链接查看:https://www.yuque.com/leyulv-uvbgk/yf80ad/vrpi9t#cHNKM
2、 预渲染是什么?如何使用?prerender-spa-plugin
单页面和多页面区别以及各自痛点?
多页面应用:
- 由前端绘制好页面套死数据,后端根据页面套模板。
- 客户端请求页面,每次返回对应的html、js等,导致页面切换加载缓慢,用户体验不好
- 无法实现转场动画
- 开发成本较低,但重复代码较多
- 维护成本高
- seo好
- 不用暴露接口,安全性较好、
两个痛点:1、页面加载缓慢 2、后期维护成本高
单页面应用
- 第一次请求返回所有html、css、js文件
- 返回的html里一开始只有一个app标签,不利于SEO
- 页面通过js框架渲染,压力在客户端,在 js 渲染页面的时候会存在一定时间白屏
- 使用前端路由的方式进行页面切换,数据向后端请求,页面无刷新用户体验好
两个痛点:1、不利于SEO 2、首屏加载慢/白屏时间
单页面痛点及解决方案对比
解决方案:预渲染、SSR

为什么要做预渲染?
做SEO是需要获取到页面真实内容的,比如h1是什么h2标签的内容是什么。但是客户端渲染时做不到的,我们使用的是vue,react、js进行渲染,因为一开始的时候只有一个脚本app标签,然后我们通过写一大堆的vue组件,把这些组件挂载到这个app标签上,本质上这个页面是什么内容都没有的,只有app标签。seo拿到这个空页面没有内容解析。
预渲染原理?
先在自己的服务器装一个无头浏览器,去请求单页面应用,让无头浏览器渲染单页面应用,然后再把渲染好的,有内容的页面返回给浏览器进行SEO。
启动启动一个本地的服务器
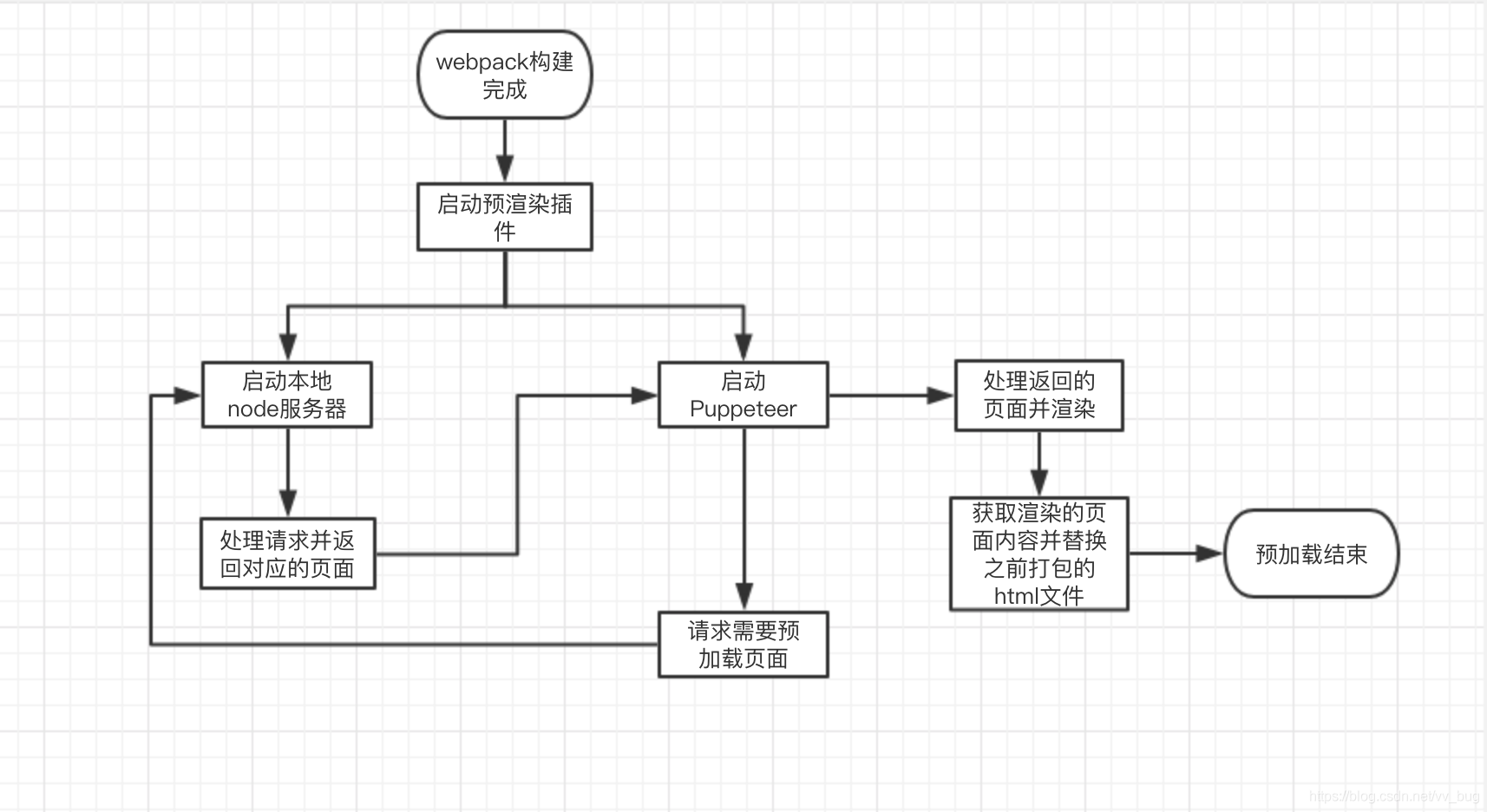
https://juejin.cn/post/6844903924265123853
SSR Nuxt原理
不过,对于我来说VUE服务端渲染最大优势是它既能拥有直输型web应用的能力
还能享受MVVM前后端分离框架开发的效率与便利
最妙的是SSR首屏渲染输出后,前端就被VUE接管,优雅地变成了单页应用
https://juejin.cn/post/6844903920590913544#heading-0
webpack打包构建
我们的服务端代码和客户端代码通过webpack分别打包,生成Server Bundle和Client Bundle,前者会运行在服务器上通过node生成预渲染的HTML字符串,发送到我们的客户端以便完成初始化渲染;而客户端bundle就自由了,初始化渲染完全不依赖它了。客户端拿到服务端返回的HTML字符串后,会去“激活”这些静态HTML,是其变成由Vue动态管理的DOM,以便响应后续数据的变化。
剖析运行流程
到这里我们该谈谈ssr的程序是怎么跑起来的了。首先我们得去构建一个vue的实例,也就是我们前面构建流程中说到的app.js做的事情,但是这里不同于传统的客户端渲染的程序,我们需要用一个工厂函数去封装它,以便每一个用户的请求都能够返回一个新的实例,也就是官网说到的避免交叉污染了。
然 后我们可以暂时移步到服务端的entry中了,这里要做的就是拿到当前路由匹配的组件,调用组件里定义的一个方法(官网取名叫asyncData)拿到初始化渲染的数据,而这个方法要做的也很简单,就是去调用我们vuex store中的方法去异步获取数据。
接下来node服务器如期启动了,跑的是我们刚写好的服务端entry里的函数。在这里还要做的就是将我们刚刚构建好的Vue实例渲染成HTML字符串,然后将拿到的数据混入我们的HTML字符串中,最后发送到我们客户端。
打开浏览器的network,我们看到了初始化渲染的HTML,并且是我们想要初始化的结构,且完全不依赖于客户端的js文件了。再仔细研究研究,里面有初始化的dom结构,有css,还有一个script标签。script标签里把我们在服务端entry拿到的数据挂载了window上。原来只是一个纯静态的HTML页面啊,没有任何的交互逻辑,所以啊,现在知道为啥子需要服务端跑一个vue客户端再跑一个vue了,服务端的vue只是混入了个数据渲染了个静态页面,客户端的vue才是去实现交互的!
https://juejin.cn/post/6844903609667158030
前端渲染的发展历程
https://juejin.cn/post/7002151207762395172

边缘渲染:https://juejin.cn/post/7002151207762395172(字节前端架构)
后面随着边缘计算的发展,由于CDN节点距离用户更近,有更短网络延时的优势,我们可以将页面进行动静拆分,将静态内容缓存在CDN先快速返回给用户,然后在CDN节点上发起动态内容的请求,之后将动态内容与静态部分以流的形式进行拼接,从而进一步提高了用户的首屏加载时间,尤其在边缘地区或者弱网环境也有能拥有很好的用户体验,此外还减少原先SSR服务器压力。
流式渲染:https://juejin.cn/post/6953819275941380109
CSR与SSR的共同点是,先返回了 HTML,因为 HTML 是一切的基础。
之后 CSR 先返回了 js,后返回了 data,在首次渲染之前页面就已经可交互了。
而 SSR 先返回了 data,后返回 js,页面在可交互前就完成了首次渲染,使用户可以更快的看到数据。
但是,先返回 js 还是先返回 data,这两者并不冲突,不应该是阻塞串行的,而应该是并行的。
它们的阻塞导致了在 FP 与 TTI 之间总有一段时间效果不如人意。为了使它们并行,来进一步提高渲染速度,我们需要引入流式服务端渲染(Steaming Server Side Render)渲染 的概念。
为什么要叫“流式服务端渲染”?是因为返回html的那个请求的相应体是流(stream),流中会先返回如骨架屏/fallback的同步HTML代码,再等待数据请求成功,返回对应的异步HTML代码,都返回后,才会关闭此HTTP连接。
本地渲染:NSR
https://www.cnblogs.com/qianduanpiaoge/p/14887276.html
孤岛渲染
3、单点登录
单点登录本质是要实现登陆一次可以在不同网站点上保存登录状态,那么我们在正常情况下是通过cookie + session来保持会话状态的,如果有办法将存有登录信息的cookie在其他站点访问的话,那么我们理论上就能实现单点登录。
而cookie是不能跨域访问的 ——解决办法:将cookie的domain域设置为二级域名。
SSO解决方案
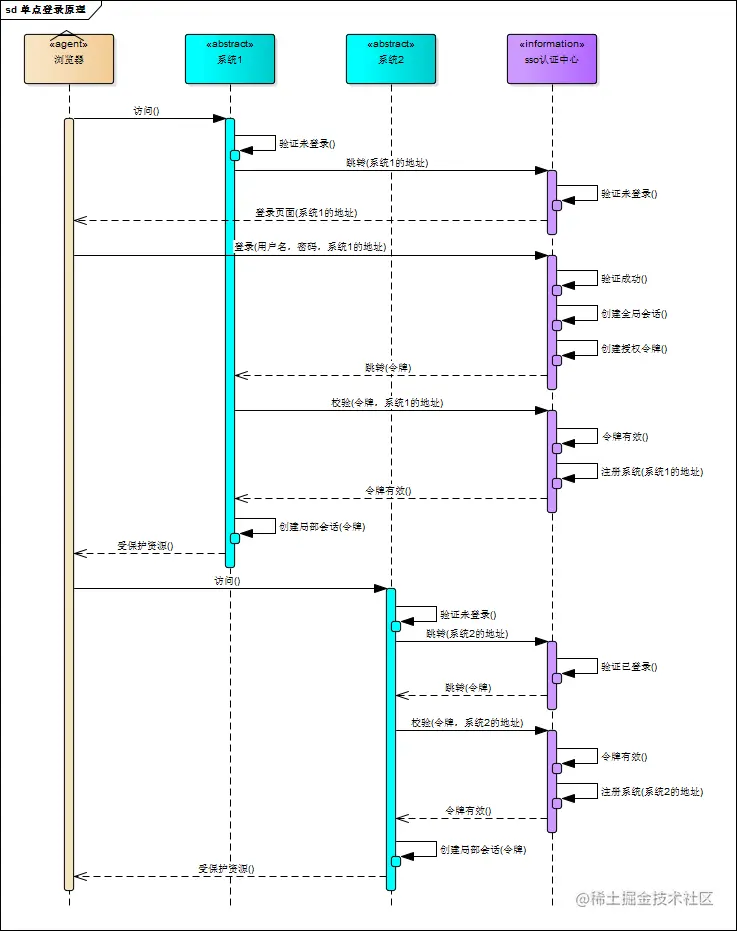
- 用户访问系统1的受保护资源,系统1发现用户未登录,跳转至sso认证中心,并将自己的地址作为参数
- sso认证中心发现用户未登录,将用户引导至登录页面(带系统1地址)
- 用户输入用户名密码提交登录申请
- sso认证中心校验用户信息,创建用户与sso认证中心之间的会话,称为全局会话(这时该会话信息保存到cookie中),同时创建授权令牌
- sso认证中心带着令牌跳转到最初的请求地址(系统1)
- 系统1拿到令牌,去sso认证中心校验令牌是否有效
- sso认证中心校验令牌,返回有效,注册系统1
- 系统1使用该令牌创建与用户的会话,称为局部会话(seesion),返回受保护资源
- 用户访问系统2的受保护资源
- 系统2发现用户未登录,跳转至sso认证中心,并将自己的地址和之前和sso认证中心的会话cookie信息作为参数
- sso认证中心发现用户已登录,跳转回系统2的地址,并附上令牌
- 系统2拿到令牌,去sso认证中心校验令牌是否有效
- sso认证中心校验令牌,返回有效,注册系统2
- 系统2使用该令牌创建与用户的局部会话,返回受保护资源
作者:小伙子vae
链接:https://juejin.cn/post/7044328327762411534
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3、防抖和节流具体场景如何使用
4、文件上传下载流程?图片如何压缩?
- 要用canvas实现前端的图片压缩,有几个步骤。
1.拿到图片元素。
2.绘制一个空白的canvas。
3.将图片绘制在canvas上。
4.将canvas转成base64。(这里调用的方法可以实现压缩,base64就可以直接放入src或者传入后端、转成别的格式传输等。)
上代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<img src="test.png" style="width: 200px; height: 400px;" id="imgBefore">
<img src="" id="imgafter"> //待会压缩完的图片放入这里。
</body>
</html>
<script>
var img = document.getElementById('imgBefore') //拿到图片元素
img.setAttribute("crossOrigin",'Anonymous') //这句话并不是必要的,如果你的图片是一个网络链接,
//那么canvas绘制时可能会报错,是因为跨域的安全性问题。报错时加上就对了。
img.onload = ()=>{ //要确保图片已经加载完才进行绘制,不然拿不到图片元素会绘制出全黑的区域,就是失败。
var width = img.width
var height = img.height
var canvas = document.createElement('canvas');
var ctx = canvas.getContext('2d');
canvas.width = width;
canvas.height = height; //以上几步都在绘制一个canvas
ctx.drawImage(img,0,0,width,height);//将图片绘制进去,这里第一个参数可以接受很多格式,
//以元素为例子,详情https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/drawImage
var base64 = canvas.toDataURL('image/jpeg',0.2); //第二个参数为压缩的比例,越小越模糊。0-1
document.getElementById('imgafter').src = base64
}
</script>
图片压缩&spm=1018.2226.3001.4187
5、图片懒加载如何实现
为什么要使用图片懒加载
在一些图片比较多的网站(比如说大型电商网站)图片是非常多的,如果我们在打开网页的一瞬间就把网站的所有图片加载出来,很有可能造成卡顿和白屏的现象,用户体验变得极其的差.
因为图片真的很多,一瞬间就把网站的所有图片加载出来浏览器短时间内根本处理不完,但是我们打开网站的那一瞬间仅仅只能看到视口内的图片,这时候去加载网页最底部的图片是非常浪费资源和没有必要的,所以遇到这种情况使用懒加载技术就显得尤为必要了。
如何实现图片懒加载
1、计算图片是否进入可视区域
**获取窗口显示区的高度:window.innerHeight**
**获取图片到视窗顶部的距离:使用元素的 getBoundingClientRact().top**
图片可以看见时条件:图片到视窗顶部的距离 < 窗口显示区的高度
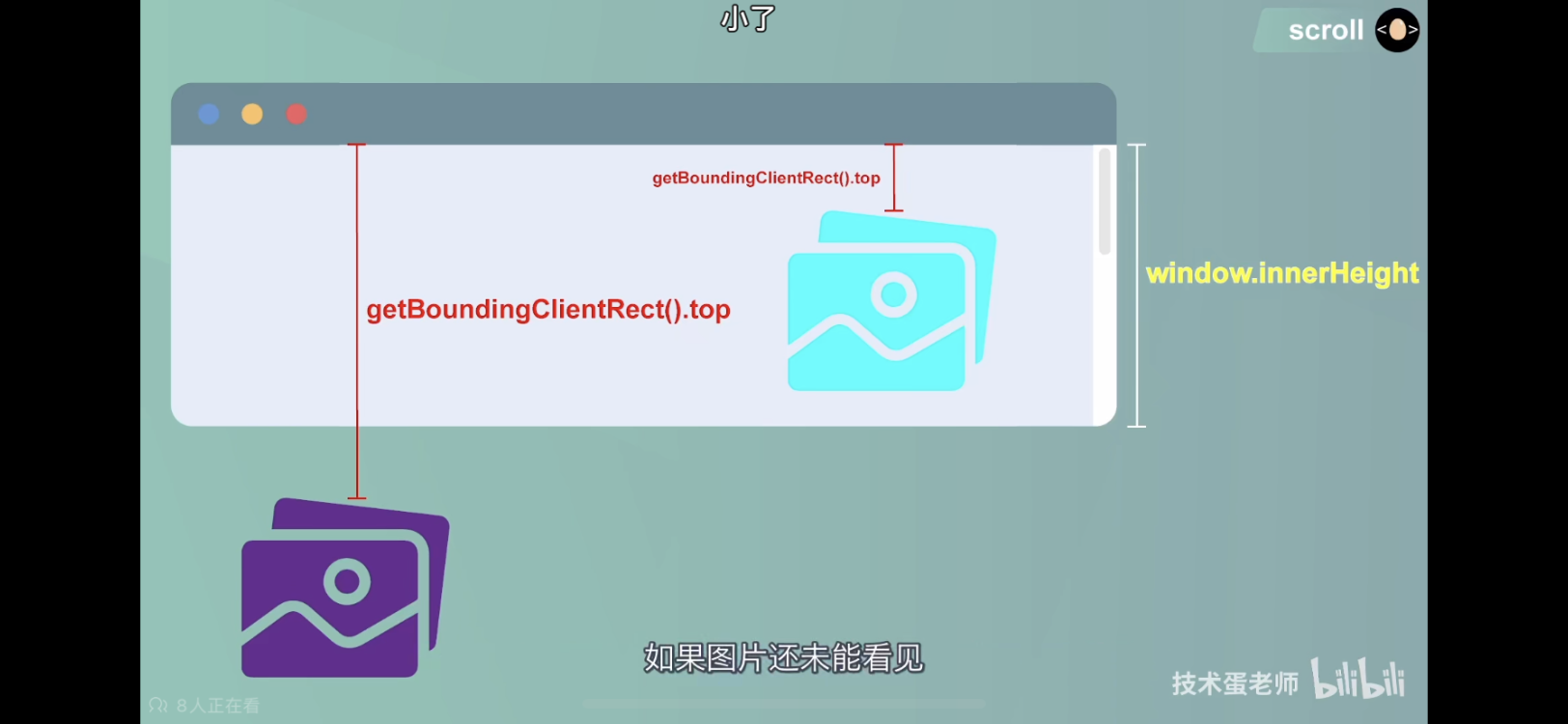
2、将图片的 src 真正的值用 data-src(自定义属性)进行替换
// 获取所有图片节点
const images = document.querySelectAll('img')
// 给window添加滚动监听事件
windows.addEventListener('scroll', (e) => {
// 遍历每个图片,获取他们到视窗顶部的距离
images.forEach(image => {
const imageTop = image.getBoundingClientRect().top
// 如果图片在可视区则将src替换
if(imgageTop < window.innerHeight) {
// 获取 data-src 属性值
const data_src = imge.getAttribute('data-src')
// 将 data-src 值赋给src
image.setAttribute('src', data_src)
}
})
})
然鹅,这种方法并不是最佳解决方案
他存在弊端,他的性能不是很好,sroll 会被触发很多次,即使图片已经加载了还是会不断触发事件,非常消耗资源.
补充新增API:IntersectionObserver
它是浏览器提供的API,字面意思交叉观察—m目标元素和可是窗口会产生交叉区域。
需要考虑兼容性。
// 接收两个参数 callback:可见性变化时的回调函数;option: 配置对象
const observer = new InterSectionObserver()
// 给元素添加监听事件---observe()方法
observer.observe(DOM节点)
// 取消监听---unobserve()方法(当图片加载完成时,便不必观察)
observer.unobserve(DOM节点)
// callback函数接受的参数entry.isIntersecting属性可以判断元素是否在可视区域
const images = document. querySelectorAll("img");
// callback 函数接收一个entries数组——添加了observe事件的元素
const callback = entries => {
entries. forEach( entry =>{
if( entry.isIntersecting ){
const image =entry.target;
const data_src= image.getAttribute(• 'data-src')
image.setAttribute('src', data-src);
observer.unobserve( image );
console.log("触发");
}
}
}
const observer = new IntersectionObserver( callback)
images. forEach( image => {
observer.observe( image );
}):
6、首屏优化方案
1、路由懒加载
2、vue.config.js 修改 productionSourceMap 为 false
productionSourceMap: false
3、首屏请求优化
vue 脚手架默认开启了 preload 与 prefetch,当我们项目很大时,这个就成了首屏加载的最大元凶了
- preload 与 prefetch 都是一种资源预加载机制;
- preload 是预先加载资源,但并不执行,只有需要时才执行它;
- prefetch 是意图预获取一些资源,以备下一个导航/页面使用;
- preload 的优先级高于 prefetch。
//vue.config.js
chainWebpack(config) {
config.plugins.delete('preload') // 删除默认的preload
config.plugins.delete('prefetch') // 删除默认的prefetch
}
作者:呛再首
链接:https://juejin.cn/post/7117515006714839047
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
4、图片压缩;
webp为什么小?比png、jpg小30% –有损WebP压缩使用预测编码来编码图像,VP8视频编解码器使用相同的方法来压缩视频中的关键帧。预测编码使用相邻像素块中的值来预测块中的值,然后仅对差异进行编码。
5、配置使用 CDN 方式引入资源库
6、开启gzip压缩
7、Treeshaking
具体来说,在 webpack 项目中,有一个入口文件,相当于一棵树的主干,入口文件有很多依赖的模块,相当于树枝。实际情况中,虽然依赖了某个模块,但其实只使用其中的某些功能。通过 tree-shaking,将没有使用的模块摇掉,这样来达到删除无用代码的目的。
本质通过减少js文件体积达到优化,因为js 文件通常需要通过请求获取。
原理:ES6模块依赖关系是确定的,和运行时的状态无关,可以进行可靠的静态分析,这就是tree-shaking的基础。简单来说这就是所谓的Tree Shaking: 基于 ES Module 规范的 Dead Code Elimination 技术,它会在运行过程中静态分析模块之间的导入导出,确定 ESM 模块中哪些导出值未曾其它模块使用,并将其删除,以此实现打包产物的优化。
链接:https://juejin.cn/post/6844903544756109319
为什么有了treeshaking 和 babel-plugin-component
首先,在老版本的webpack中是不支持将代码编译成为Es module模块的,所有就会导致一些组件库编译后的代码无法使用Tree Shaking进行处理。(因为它编译出来的代码压根就不是ES Module呀!)
所以老版本组件库中,比如element-ui中借用babel-plugin-component,老版本ant-design使用babel-plugin-import进行分析代码从而实现Tree Shaking的效果。
[https://blog.csdn.net/lunahaijiao/article/details/121368958?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166761258316782429762790%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=166761258316782429762790&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-2-121368958-null-null.142^v63^control,201^v3^add_ask,213^v1^control&utm_term=treeshaking%20%E5%92%8Ccomponent&spm=1018.2226.3001.4187](https://blog.csdn.net/lunahaijiao/article/details/121368958?ops_request_misc=%7B%22request%5Fid%22%3A%22166761258316782429762790%22%2C%22scm%22%3A%2220140713.130102334.pc%5Fall.%22%7D&request_id=166761258316782429762790&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-2-121368958-null-null.142^v63^control,201^v3^add_ask,213^v1^control&utm_term=treeshaking 和component&spm=1018.2226.3001.4187)
7、****小图标把图片替换成 svg;
8、骨架屏
9、路由跳转加动画
- 从减少代码体积角度的:webpack优化、打包优化、tree-shaking等
- 从减少HTTP请求角度的:接口合并、按需加载、延时加载等各种方法减少请求
- 从缓存角度出发:离线包、http&浏览器各种缓存使用、dns预解析、dll方案、接口缓存方案等
- 从数据获取时机角度出发:webWorker预取数据、路由进入过程读取数据等
- 从减少图片体积和数量出发:使用webp图片、请求域名并行优化、CSS Sprite等
3、前端性能优化有哪些指标?怎么查看,还知道什么解决方案
有一篇文章写到,亚马逊减少了100ms的白屏时间,销量增加1% ! 由此可见性能优化的重要性了吧

一、确定指标
首先我们得确定具体的指标,没有具体的指标就是空谈。
二、性能优化有迹可循
从url按下回车键…..
1.输入网址url
2.缓存解析(浏览器缓存-系统缓存-路由器缓存)等
3.域名解析(DNS解析,域名到ip地址的解析)
— 拿到 ip 地址可以使用 cdn 加速
4.TCP连接,三次握手
—减少请求数量,合并接口,使用精灵图
5.服务器接收到浏览器发送的请求信息,返回响应头与响应体
— 对响应报文进行压缩,gzip压缩,
webpack压缩:treeshaking、关闭productionSourceMap( vue.config.js 修改 productionSourceMap 为 false
)
6.页面渲染-浏览器接收到响应信息后,进行客户端渲染,生成DOM树、解析CSS样式对JS进行交互。
—从框架的角度:关闭 preload 与 prefetch、路由懒加载、
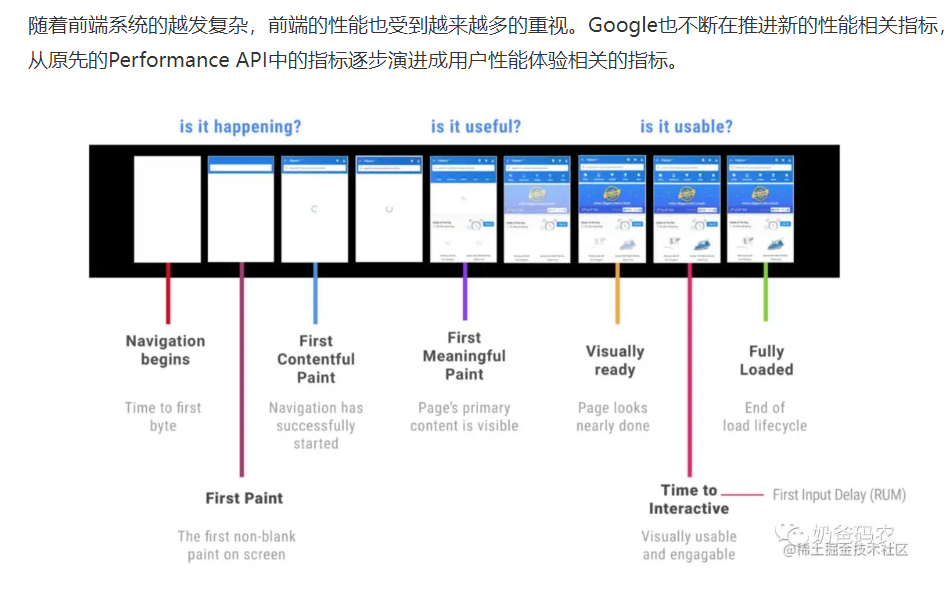
Performance API
https://www.yuque.com/leyulv-uvbgk/ew73lz/thklgm
这个是HTML5新增的API,可供查询早期看见有些人在页面加载时,的head里面添加上一段获取时间戳的代码,然后在开始获取数据的时候在获取一次时间戳,相减来计算白屏时间这其实是一种非常麻烦的做法,并不友好。因此W3C后面推出了Performance这个API来帮助开发者查看这些性能时间点。
直接F12.控制台输入window.perforamce.timing
你可以看到一大堆这些属性,细心的你一定会发现这是成对出现的没错。下面把具体的都写在底下了。
const timingInfo = window.performance.timing;
// DNS解析,DNS查询耗时
timingInfo.domainLookupEnd - timingInfo.domainLookupStart;
// TCP连接耗时
timingInfo.connectEnd - timingInfo.connectStart;
// 获得首字节耗费时间,也叫TTFB
timingInfo.responseStart - timingInfo.navigationStart;
// domReady时间(与DomContentLoad事件对应)
timingInfo.domContentLoadedEventStart - timingInfo.navigationStart;
// DOM资源下载
timingInfo.responseEnd - timingInfo.responseStart;
// 准备新页面时间耗时
timingInfo.fetchStar - timingInfo.navigationStart;
// 重定向耗时
timingInfo.redirectEnd - timingInfo.redirectStart;
// Appcache 耗时
timingInfo.domainLookupStart - timingInfo.fetchStart;
// unload 前文档耗时
timingInfo.unloadEventEnd - timingInfo.unloadEventStart;
// request请求耗时
timingInfo.responseEnd - timingInfo.requestStart;
// 请求完毕至DOM加载
timingInfo.domInteractive - timingInfo.responseEnd;
// 解释dom树耗时
timingInfo.domComplete - timingInfo.domInteractive;
// 从开始至load总耗时
timingInfo.loadEventEnd - timingInfo.navigationStart;
// 白屏时间
timingInfo.responseStart - timingInfo.fetchStart;
// 首屏时间
timingInfo.domComplete - timingInfo.fetchStart;
1.FP
FP(First Paint)翻译为首次绘制,表示浏览器第一次向屏幕传输像素的时间点,可以理解为浏览器首次开始绘制像素,页面首次在屏幕上发生了视觉变化 。听起来是不是很烦人?不过问题不大 你只要知道有这么个东西就行了,因为这个指标有虽然有但没啥子意义可言。
2.FCP
指浏览器从响应用户输入网络地址到页面内容的任何部分在屏幕上完成渲染的时间。这个就是实际有意义的首屏时间。这个指标就是我们常说的白屏时间
3.FMP
FMP(First Meaningful Paint)首次进行有意义的绘制,这个指标反应就是主要内容出现在页面上要的时间,FMP的本质是一个主观认知的指标,是用一个算法来计算那个时间点是FMP,计我们网易这边目前看的指标是FMP。
首次有效绘制 = 具有最大布局变化的绘制
[https://www.zhihu.com/search?type=content&q=First%20Meaningful%20Paint](https://www.zhihu.com/search?type=content&q=First Meaningful Paint)
4.LCP
LCP(Largest Contentful Paint)翻译为最大内容绘制,用于记录首屏中最大元素渲染的时间,和 FCP 不同的是,FCP 更关注浏览器什么时候开始绘制内容,比如一个 loading 页面或者骨架屏,并没有实际价值,所以 LCP 相较于 FCP 更适合作为首屏指标。我有个好朋友在阿里那边,他们组的指标主要是看LCP,但我们组这边觉得LCP在设备兼容性上还不够完善,目前只在安卓8以上,以及pc上chrome支持。
5.TTI
TTI(Time to Interactive)翻译为交互时间,等到服务器通过HTTP协议将响应全部返回之后,便开始DOM Tree 的构建,完成之后,网页变成可交互状态,到此为止便是网页的可交互时间。用户可以进行正常的事件输入交互操作。
项目业务亮点
1、单点登录技术有几种?如何实现?
2.实现方法
- 前端实现单点登录的关键就在于共享SessionID或者Token在cookie中
- cookie的domain属性的有效值为当前域或者其父级作用域的域名/ip地址
2.1 父域Cookie实现 同一域名的情况下(不支持跨域)
可以将当前cookie的domain设置为父域,父域cookie的domain会自动共享给子域domain属性;
将cookie的path设置为根路径”/“,换言之就是将sessionId和token设置给父域,其下面的子系统就可以访问到这个cookie。
- token + 单点登录(localStorage跨域存储)
可以选择将 Session ID (或 Token )保存到浏览器的 LocalStorage 中,让前端在每次向后端发送请求时,主动将LocalStorage的数据传递给服务端
这些都是由前端来控制的,后端需要做的仅仅是在用户登录成功后,将 Session ID(或 Token)放在响应体中传递给前端
单点登录完全可以在前端实现。前端拿到 Session ID(或 Token )后,除了将它写入自己的 LocalStorage 中之外,还可以通过特殊手段将它写入多个其他域下的 LocalStorage 中
// 获取 token
var token = result.data.token;
// 动态创建一个不可见的iframe,在iframe中加载一个跨域HTML
var iframe = document.createElement("iframe");
iframe.src = "http://app1.com/localstorage.html";
document.body.append(iframe);
// 使用postMessage()方法将token传递给iframe
setTimeout(function () {
iframe.contentWindow.postMessage(token, "http://app1.com");
}, 4000);
setTimeout(function () {
iframe.remove();
}, 6000);
// 在这个iframe所加载的HTML中绑定一个事件监听器,当事件被触发时,把接收到的token数据写入localStorage
window.addEventListener('message', function (event) {
localStorage.setItem('token', event.data)
}, false);
2.2 统一认证中心实现 不同域名(支持跨域)
- 认证中心(SSO)就是一个专门负责处理登录请求的独立web服务;
- 用户统一在认证中心进行登录,认证中心登录后将token写入cookie(此cookie是认证中心独有的),子应用系统访问不到
- 目标应用系统登录检查当前用户有没有token,如果没有则说明用户没有登录当前系统,将跳转到认证中心(跳转时会自动带上认证中心的cookie,因此认证中心会知道当前用户是否已经登录过了);
- 如果没有则返回登录页面进行登录;
- 如果已经登录过则会跳转到目标URL并在跳转前生成一个token拼接在URL后回传给目标应用系统,
- 目标系统拿到token向认证中心确认token合法性;
- 目标系统记录用户token登录状态,并将token写入cookie后放行进入(此cookie也是当前应用系统独有),其他子系统无法访问;
- 用户再次访问目标应用系统时会自动带上token,系统验证token进行登录,脱离认证中心。
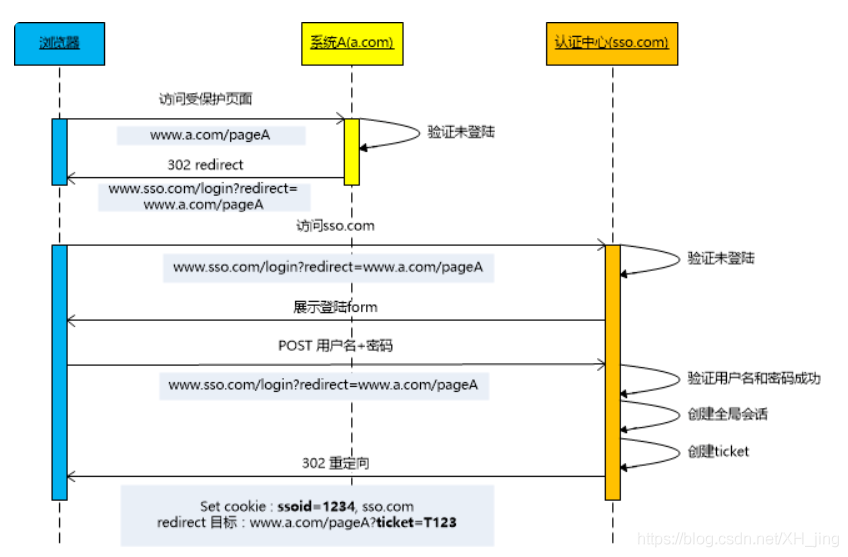
————————————————
版权声明:本文为CSDN博主「ZhenYu学前端」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_46077258/article/details/125997620
2、JS 大数据问题?小数字问题?有什么 解决办法?
3、VUEX 和 localStorage?
4、全局事件总线原理?设计模式?
ipad面试准备P4
移动端适配方案
Vue-cli
如何封装一个组件
就拿modal弹窗具体。
1、首先封装一个组件我们需要考虑,我们应该需要向外暴露哪些接口,需要外部传入哪些数据进来,合理的抽离公共部分和定制部分。
2、一个弹窗包括哪些内容?Title、content、ok回调、cencel回调,那我们就在props里面接收这几个参数。
3、Tile、content放在哪?Title我们可以以值得方式传入,样式写死。但是content比较灵活,可以用插槽的方式实现,组件标签中传入模板灵活定制
过程中出现的问题?
遮罩层不能完全盖住所有的东西,就算设置z-index也不管用。什么原因?因为z-index值只决定同一父元素中的同级子元素的堆叠顺序。解决方案:使用Teleport瞬移组件,将组件添加到 body 下。

项目遇到的问题
JS大数字和小数字问题
场景:当axios内部进行JSON.parse()将服务器返回的字符串转换为对象之后, 文章的ID值会不准确
JavaScript 能够准确表示的整数范围在-2^53到2^53之间(不含两个端点),超过这个范围,无法精确表示这个值,这使得 JavaScript 不适合进行科学和金融方面的精确计算。
关于一些json方法:
JSON 的常规用途是同 web 服务器进行数据传输。
在从 web 服务器接收数据时,数据永远是字符串。
通过 JSON.parse() 解析数据,这些数据会成为 JavaScript 对象。
/*将服务器端接受的数据转换为js对象*/
JSON.parse()
在向 web 服务器发送数据时,数据必须是字符串。
通过 JSON.stringify() 把 JavaScript 对象转换为字符串。
/*将js对象转换为字符串发送给服务器*/
JSON.stringify()
json-bigint 会把超出 JS 安全整数范围的数字转为一个 BigNumber 类型的对象,对象数据是它内部的一个算法处理之后的,我们要做的就是在使用的时候转为字符串来使用。
axios 为了方便我们使用数据,它会在内部使用 JSON.parse() 把后端返回的数据转为 JavaScript 对象,
解决思路:
Axios 会在内部使用 JSON.parse 把后端返回的数据转为 JavaScript 数据对象。
所以解决思路就是:不要让 axios 使用 JSON.parse 来转换这个数据,而是使用 json-biginit 来做转换处理。
axios 提供了一个 API:transformResponse,在这里对返回的原数据进行操作
滚动列表卡顿
首屏加载卡顿
-图片懒加载
vue.set() 数据响应式
简历涉及技能知识点
HTML、CSS方面
H5+CS3新特性
P16
HTML+CSS页面布局(可能考垂直居中)
水平垂直居中的几种方法:P17
felx布局
flex布局:P31
rem、布局移动端适配
P26
视口
- layout viewport(布局视口):在PC端上,布局视口等于浏览器窗口的宽度。而在移动端上,由于要使为PC端浏览器设计的网站能够完全显示在移动端的小屏幕里,此时的布局视口会远大于移动设备的屏幕,就会出现滚动条。js获取布局视口:
**document.documentElement.clientWidth**| document.body.clientWidth; - visual viewport(视觉视口):用户正在看到的网页的区域。用户可以通过缩放来查看网站的内容。如果用户缩小网站,我们看到的网站区域将变大,此时视觉视口也变大了,同理,用户放大网站,我们能看到的网站区域将缩小,此时视觉视口也变小了。不管用户如何缩放,都不会影响到布局视口的宽度。js获取视觉视口:
**window.innerWidth**; - ideal viewport(理想视口):布局视口的一个理想尺寸,只有当布局视口的尺寸等于设备屏幕的尺寸时,才是理想视口。js获取理想视口:
window.screen.width;
1、在桌面浏览器上,浏览器窗口与视口的宽度一致,而视口(CSS标准文档中称为“初始包含块”)是CSS百分比宽度推算的根源,因此,浏览器窗口是约束CSS布局的视口;
2、在手机上,有两个视口,布局视口会限制CSS布局;视觉视口决定用户看到的网站内容;
3、移动端浏览器还有个理想视口,它是对特定设备上的特定浏览器的布局视口的一个理想尺寸;
4、可以把布局视口尺寸定义为理想视口。这也是响应式设计的基础。
作者:Sun____
链接:https://www.jianshu.com/p/7c5fdf90c0ef
来源:简书
https://www.jianshu.com/p/7c5fdf90c0ef
一些移动端适配可能用到的API
获取设备像素比:**window.devicePixelRatio**
获取可视区域宽高:window.innerWidth和视觉视口高度 window.innerHeight
一些 meta 视口标签:
meta视口标签
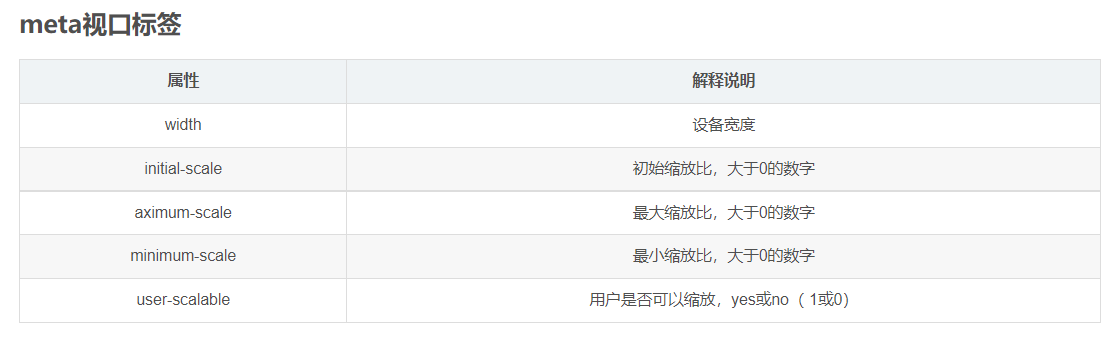
标准的viewport设置:
媒体查询
https://blog.csdn.net/dream_lifes/article/details/122013152
可以使用媒体查询结合rem布局进行适配
移动端布局主流方案

链接:https://juejin.cn/post/6844903631993454600
rem是viewport过度:https://juejin.cn/post/7084926646033055752
viewport相对于rem的优势
- 语义化更好, rem从本义上来说,是一种字体单位,不是用来做布局和各种屏幕尺寸大小适配的,如上面的示例,用rem做适配单位,计算根字体的时候,计算公式中的100这个参数让人感觉很费解,viewport词更达意。
- 可以直接在代码中书写px,借助postcss-px-to-viewport插件转换成vw单位,完美适配移动端各种屏幕尺寸。不用像之前那样,一是要在蓝湖上设置根字体基准尺寸,将设计稿标注的px单位转换成rem单位,然后摘抄到代码中。二是需要用js计算设置根字体大小。前端开发天然喜欢px单位,像rem,em,vw,vh这些单位,一般都不是UI设计稿标注的尺寸,开发时需要转换成本。不如直接在代码中写px直观高效。
作者:去伪存真
链接:https://juejin.cn/post/7084926646033055752
你的项目中用的是什么方法进行适配
我的项目适配方案:viewport + px + flex
实习公司的适配方案:媒体查询 + flex布局 + px + 适当时候的vh/vw
less预编译相关(预编译原理)
原理主要分析:
less 是预编译处理器,所以会在编译前进行处理成css
- 首先less 会转换为ast(抽象语法树)语法
- 然后遍历转换后所有的节点
- 最后再形成css树
W3C标准是什么?
web标准简单来说可以分为结构、表现和行为(三层结构)
结构 主要是有HTML标签组成
表现 即指css样式表
行为 主要是有js、dom组成
web标准一般是将该三部分独立分开,使其更具有模块化。但一般产生行为时,就会有结构或者表现的变化,也使这三者的界限并不那么清晰。
2、W3C对于WEB标准提出了规范化的要求
1)标签和属性名字母要小写
2)标签要闭合
3)标签不允许随意嵌套
4)尽量使用外链css样式表和js脚本。让结构、表现和行为分为三块,符合规范。同时提高页面渲染速度,提高用户的体验。
5)样式尽量少用行间样式表,使结构与表现分离
6)标签的id和class等属性命名要做到见文知义,更利于seo,代码便于维护
javaScrip方面
ES6新特性
P1 06
事件循环
P74
防抖节流
P75
垃圾回收机制
https://www.yuque.com/cuggz/interview/vgbphi#edbc6ae5d0930d1b2047b644faf33356
P83
原型/原型链
https://www.yuque.com/cuggz/interview/vgbphi#4fa5088a8bb423b2739ff1166ce1ac36
原型:只有函数对象上才有prototype属性,这个prototype属性上默认有一个属性constructor(构造函数)指向自己。
P71
继承
P71
1、原型链继承
2、构造函数继承(call)
3、组合式继承
闭包
P68
V8引擎原理
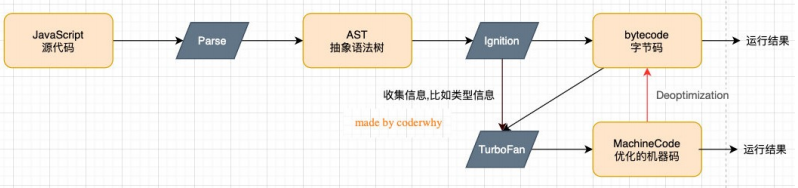
V8引擎本身的源码非常复杂,大概有超过100w行C++代码,通过了解它的架构,我们可以知道它是如何对JavaScript执行的:
Parse模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不直接认识JavaScript代码
- 如果函数没有被调用,那么是不会被转换成AST的;
- Parse的V8官方文档:https://v8.dev/blog/scanner
Ignition是一个解释器,会将AST转换成ByteCode(字节码)时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);
- 如果函数只调用一次,Ignition会执行解释执行ByteCode;
- Ignition的V8官方文档:https://v8.dev/blog/ignition-interpreter
TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码;
- 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能;
- 但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
- TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit
作者:砺能
链接:https://juejin.cn/post/7107106791778942983
浏览器渲染原理
1、构建DOM:二进制流 ->字符 ->token -> 节点对象 -> DOM树
2、构建CSSOM:二进制流 ->字符 ->token -> 节点对象 -> CSSOM
3、构建渲染树(布局):DOM和CSSOM结合
4、布局计算
1、分层(图层树) :
2、绘制列表 :把复杂图层拆分为一个个小的绘制指令,然后再按照这些指令的顺序合成一个绘制列表
3、分块 :绘制列表准备好后,渲染进程的主线程会给合成线程发送commit消息,把绘制列表提交给合成线程。合成线程再将图层划分为图块进行渲染
4、 光栅化:合成线程会按照视口附近的图块来优先生成位图,将图块转化为位图。
5、 合成显示:
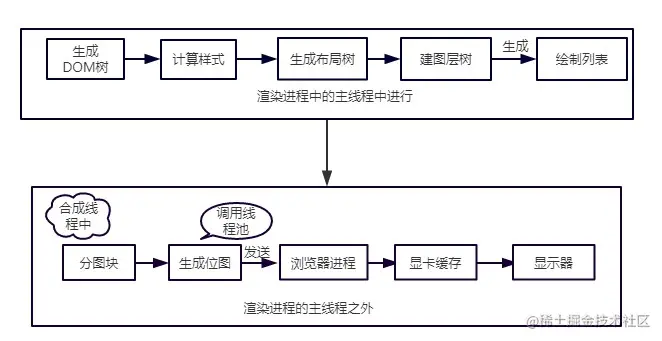
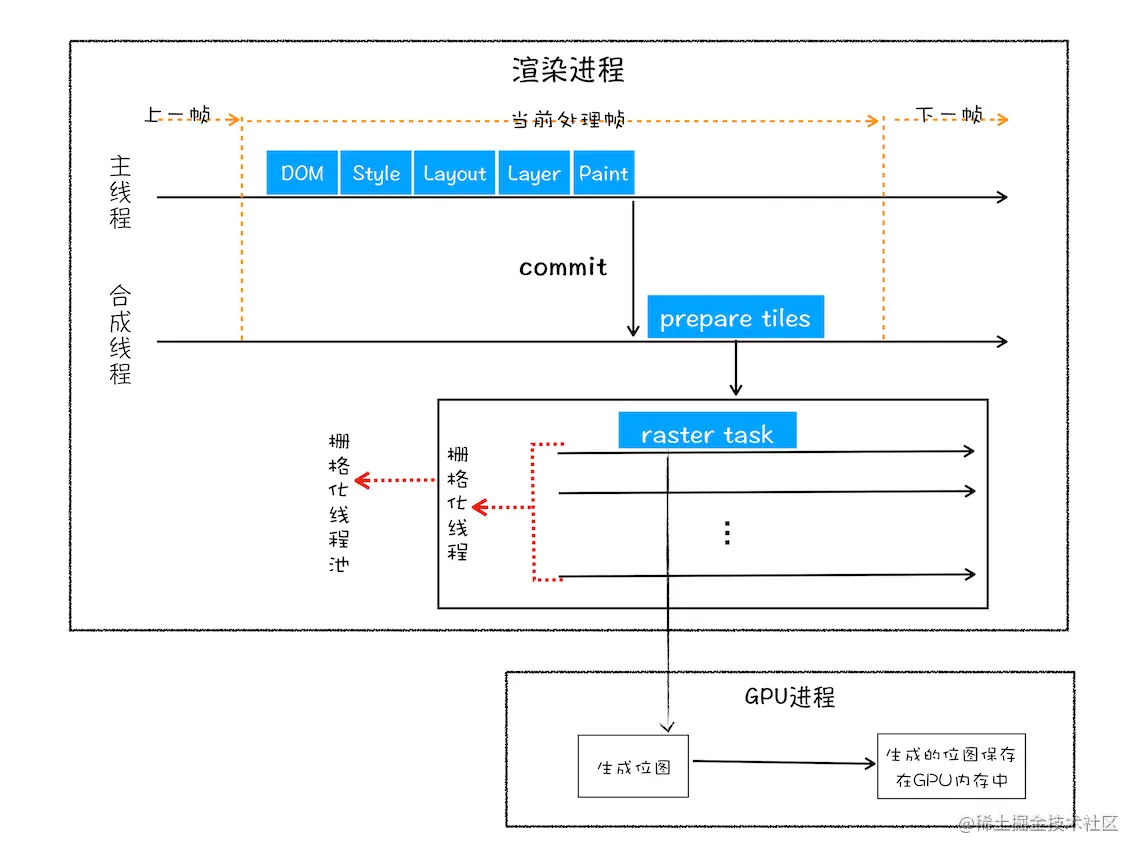
作者:TianTianUp
链接:https://juejin.cn/post/6847902222349500430
函数柯里化
核心在于:函数里面返回函数,从而做到参数复用的目的。
手撕代码文件记录
// 函数currying化实现
function Currying(fn) {
function curried(...args){
// 判断当前已经接受的参数个数,可以参数本身需要接受的参数是否已经一致了
// 1.当已经传入的参数 大于等于 需要的参数是,就执行函数
if(args.length >= fn.length) {
return fn.apply(this,args)
} else {
// 当没有达到个数时,就返回一个新的函数,继续来接受参数
function curried2(...args2) {
// 接收到参数后,需要递归调用curried来检查函数的个数是否达到
return curried.apply(this, args.concat(args2))
}
return curried2
}
}
return curried
}
function add (a,b,c) {
return a+b+c
}
let cAdd = Currying(add)
console.log(cAdd(1)(2)(3))
HTTP方面
CSRF(跨站脚本攻击)
场景:
小明登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了 10000 元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小明的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
CSRF有两个特点:
CSRF(通常)发生在第三方域名。
CSRF攻击者不能获取到Cookie等信息,只是使用。
原文链接:https://blog.csdn.net/JinYJ2014/article/details/122931481
为什么说Token可以防止CSRF攻击呢?
CSRF是用户登录安全A网站后,点击危险B网站,危险B利用A中的cookie(不是获取,只是利用登录的状态)替代用户进行危险操作。
token验证是需要将token放到请求头或者请求体里,发送给服务器进行验证。
而token虽然是存储于cookie中的,但是危险B无法获取和解析cookie也就拿不到token(不能将token放到请求头中),就无法冒用用户身份。
cookie是同源的,而打开简书的两个页面是同源的,所以这两个页面的源相同、cookie同。
原文链接:https://blog.csdn.net/qq_36582776/article/details/123598559
认证技术cookie、session、Token、jwt
P101
cookie有哪些属性?
https://juejin.cn/post/7092014317192626206#heading-0
cookie在http和https下表现
http/https属于跨域,请求接口会报错,除非解决了跨域。
如果设置了secure属性,那么cookie只能在https下传输,传输时会被加密
如果设置了sameSite
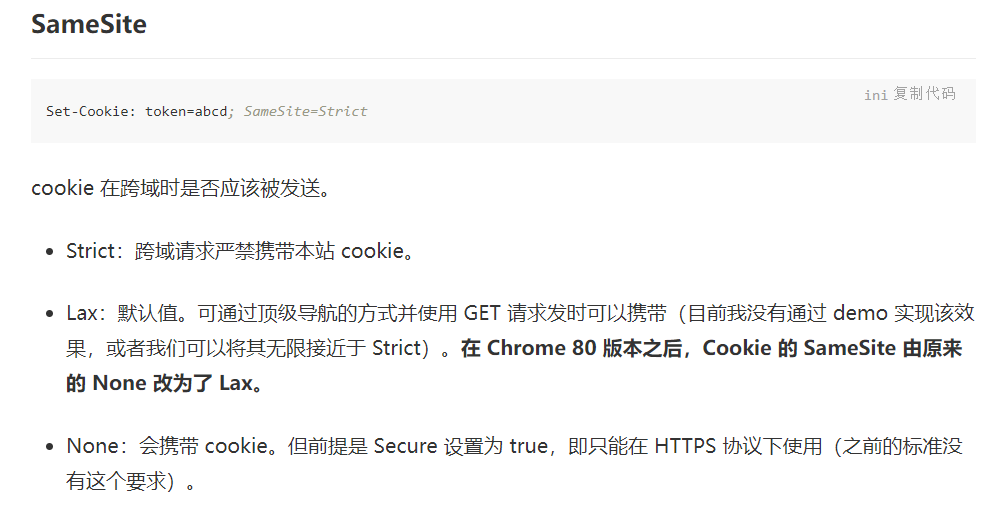
SameSite
SameSite 是最近非常值得一提的内容,因为 2 月份发布的 Chrome80 版本中默认屏蔽了第三方的 Cookie,这会导致阿里系的很多应用都产生问题,为此还专门成立了问题小组,推动各 BU 进行改造。
https://juejin.cn/post/6844904095711494151
Strict 跨站请求严禁携带本站 cookie,即当前网页 URL 与请求目标 URL 完全一致。(注意区分跨域和跨站)
Lax 允许部分第三方请求携带 Cookie(可通过顶级导航的方式并使用 GET 请求发时可以携带)
None 无论是否跨站都会发送 Cookie
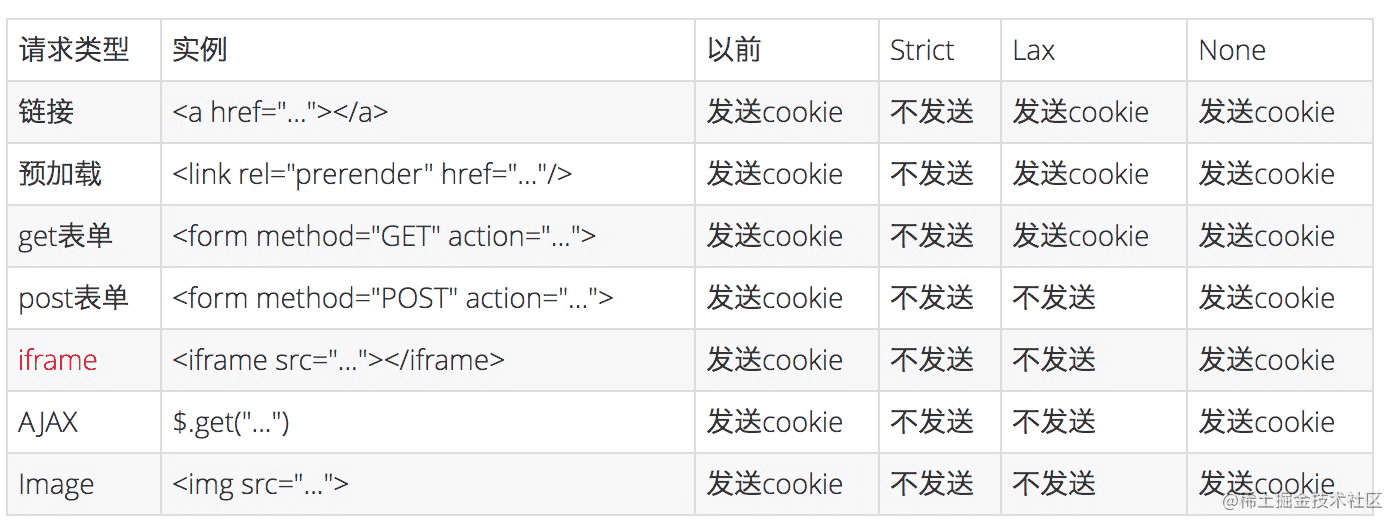
除了这些还有 script 的方式,这种方式也不会发送 Cookie,像淘宝的大部分请求都是 jsonp,如果涉及到跨站也有可能会被影响。
一些场景:
我们再看看会出现什么的问题?举几个例子:
天猫和飞猪的页面靠请求淘宝域名下的接口获取登录信息,由于 Cookie 丢失,用户无法登录,页面还会误判断成是由于用户开启了浏览器的“禁止第三方 Cookie”功能导致而给与错误的提示
淘宝部分页面内嵌支付宝确认付款和确认收货页面、天猫内嵌淘宝的登录页面等,由于 Cookie 失效,付款、登录等操作都会失败
阿里妈妈在各大网站比如今日头条,网易,微博等投放的广告,也是用 iframe 嵌入的,没有了 Cookie,就不能准确的进行推荐
一些埋点系统会把用户 id 信息埋到 Cookie 中,用于日志上报,这种系统一般走的都是单独的域名,与业务域名分开,所以也会受到影响。
一些用于防止恶意请求的系统,对判断为恶意请求的访问会弹出验证码让用户进行安全验证,通过安全验证后会在请求所在域种一个Cookie,请求中带上这个Cookie之后,短时间内不再弹安全验证码。在Chrome80以上如果因为Samesite的原因请求没办法带上这个Cookie,则会出现一直弹出验证码进行安全验证。
天猫商家后台请求了跨域的接口,因为没有 Cookie,接口不会返回数据
链接:https://juejin.cn/post/6844904095711494151
CDN原理
https://www.yuque.com/cuggz/interview/lph6i8#7ff031e1c6a1cc8ea733492b907c3493
CDN的工作原理:
(1)用户未使用CDN缓存资源的过程:
- 浏览器通过DNS对域名进行解析(就是上面的DNS解析过程),依次得到此域名对应的IP地址
- 浏览器根据得到的IP地址,向域名的服务主机发送数据请求
- 服务器向浏览器返回响应数据
(2)用户使用CDN缓存资源的过程:
- 对于点击的数据的URL,经过本地DNS系统的解析,发现该URL对应的是一个CDN专用的DNS服务器,DNS系统就会将域名解析权交给CNAME指向的CDN专用的DNS服务器。
- CND专用DNS服务器将CND的全局负载均衡设备IP地址返回给用户
- 用户向CDN的全局负载均衡设备发起数据请求
- CDN的全局负载均衡设备根据用户的IP地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求
- 区域负载均衡设备选择一台合适的缓存服务器来提供服务,将该缓存服务器的IP地址返回给全局负载均衡设备
- 全局负载均衡设备把服务器的IP地址返回给用户
- 用户向该缓存服务器发起请求,缓存服务器响应用户的请求,将用户所需内容发送至用户终端。
如果缓存服务器没有用户想要的内容,那么缓存服务器就会向它的上一级缓存服务器请求内容,以此类推,直到获取到需要的资源。最后如果还是没有,就会回到自己的服务器去获取资源。
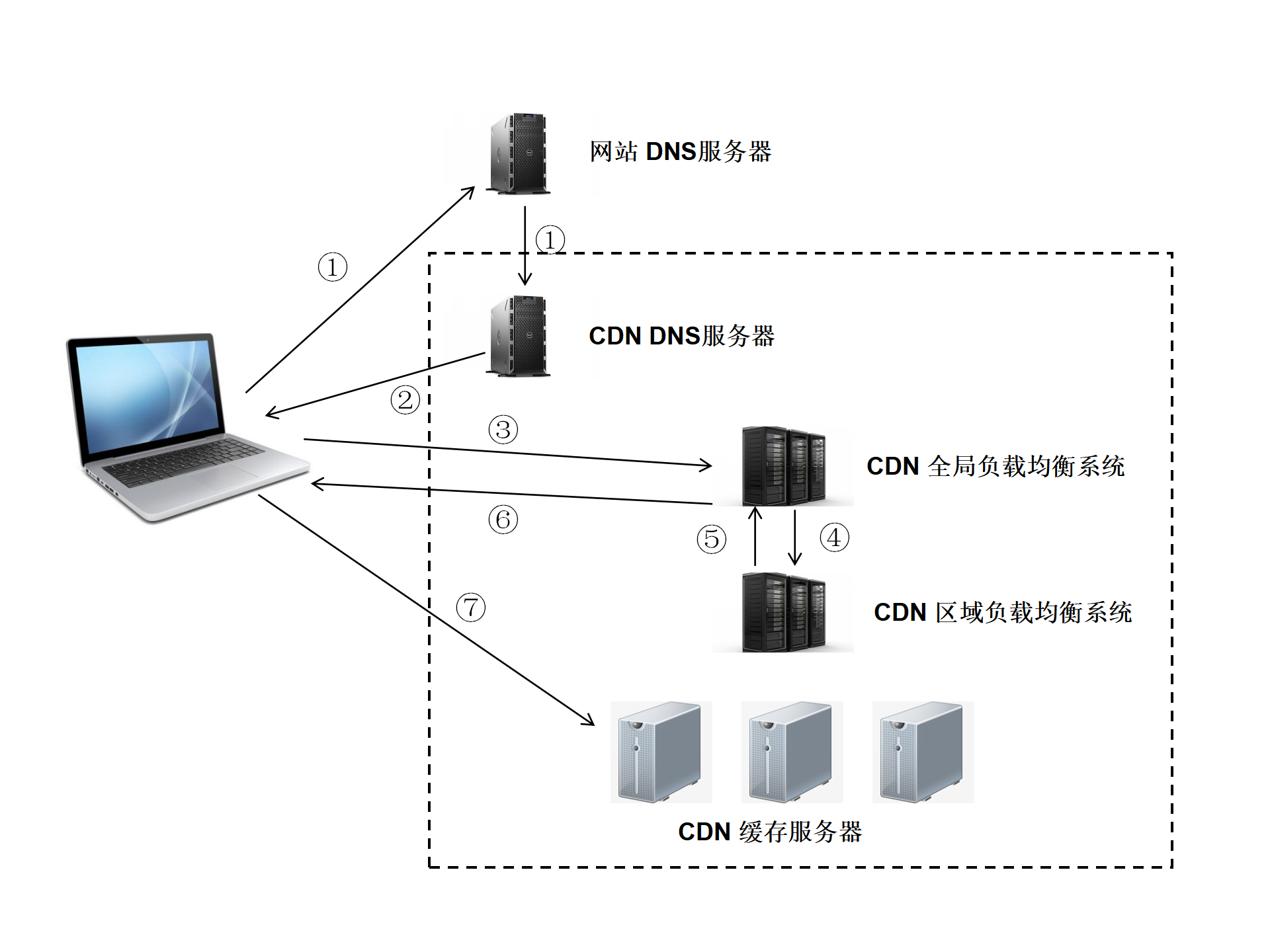
CNAME(意为:别名):在域名解析中,实际上解析出来的指定域名对应的IP地址,或者该域名的一个CNAME,然后再根据这个CNAME来查找对应的IP地址。
TCP的重传机制
由于TCP的下层网络(网络层)可能出现丢失、重复或失序的情况,TCP协议提供可靠数据传输服务。为保证数据传输的正确性,TCP会重传其认为已丢失(包括报文中的比特错误)的包。TCP使用两套独立的机制来完成重传,一是基于时间,二是基于确认信息。
TCP在发送一个数据之后,就开启一个定时器,若是在这个时间内没有收到发送数据的ACK确认报文,则对该报文进行重传,在达到一定次数还没有成功时放弃并发送一个复位信号。
TCP的流量控制机制
——解决发送和接受速率不一致问题。
一般来说,流量控制就是为了让发送方发送数据的速度不要太快,要让接收方来得及接收。TCP采用大小可变的滑动窗口进行流量控制,窗口大小的单位是字节。这里说的窗口大小其实就是每次传输的数据大小。
- 当一个连接建立时,连接的每一端分配一个缓冲区来保存输入的数据,并将缓冲区的大小发送给另一端。
- 当数据到达时,接收方发送确认,其中包含了自己剩余的缓冲区大小。(剩余的缓冲区空间的大小被称为窗口,指出窗口大小的通知称为窗口通告 。接收方在发送的每一确认中都含有一个窗口通告。)
- 如果接收方应用程序读数据的速度能够与数据到达的速度一样快,接收方将在每一确认中发送一个正的窗口通告。
- 如果发送方操作的速度快于接收方,接收到的数据最终将充满接收方的缓冲区,导致接收方通告一个零窗口 。发送方收到一个零窗口通告时,必须停止发送,直到接收方重新通告一个正的窗口。
TCP的拥塞控制机制
——解决网络自身拥堵问题(如物理设备支持最大传输带宽)
TCP的拥塞控制机制主要是以下四种机制:
- 慢启动(慢开始)
- 拥塞避免
- 快速重传
- 快速恢复
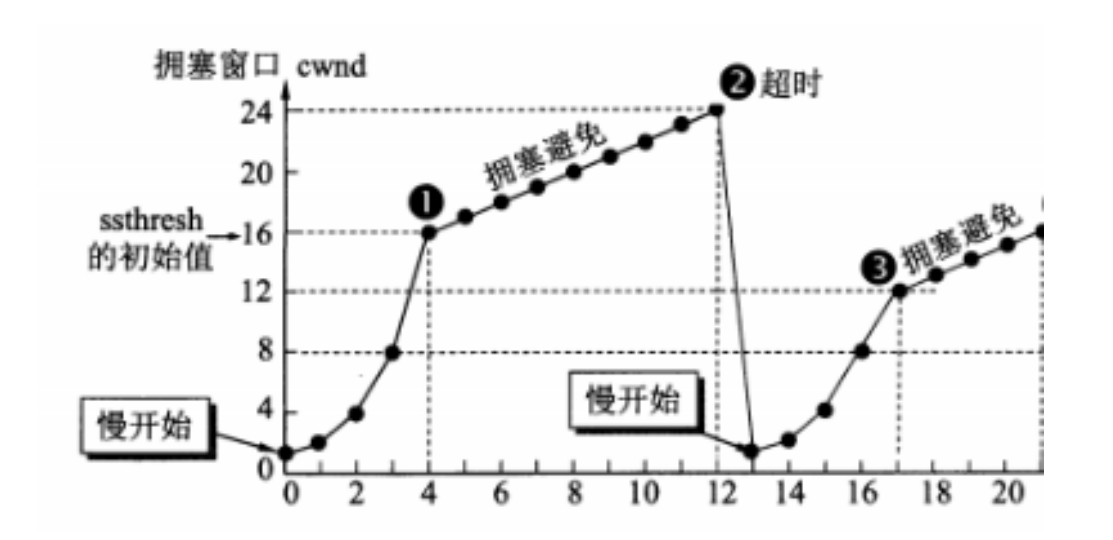
(1)慢启动(慢开始)(指数增长)
在开始发送的时候设置cwnd = 1(cwnd指的是拥塞窗口)
思路:开始的时候不要发送大量数据,而是先测试一下网络的拥塞程度,由小到大增加拥塞窗口的大小。
为了防止cwnd增长过大引起网络拥塞,设置一个慢开始门限(ssthresh 状态变量)
- 当cnwd < ssthresh,使用慢开始算法
- 当cnwd = ssthresh,既可使用慢开始算法,也可以使用拥塞避免算法
- 当cnwd > ssthresh,使用拥塞避免算法
(2)拥塞避免(线性增长)
- 拥塞避免未必能够完全避免拥塞,是说在拥塞避免阶段将拥塞窗口控制为按线性增长,使网络不容易出现阻塞。
- 思路: 让拥塞窗口cwnd缓慢的增大,即每经过一个返回时间RTT就把发送方的拥塞控制窗口加一
- 无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞,就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为1,执行慢开始算法。如图所示:
其中,判断网络出现拥塞的根据就是没有收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为无法判定,所以都当做拥塞来处理。
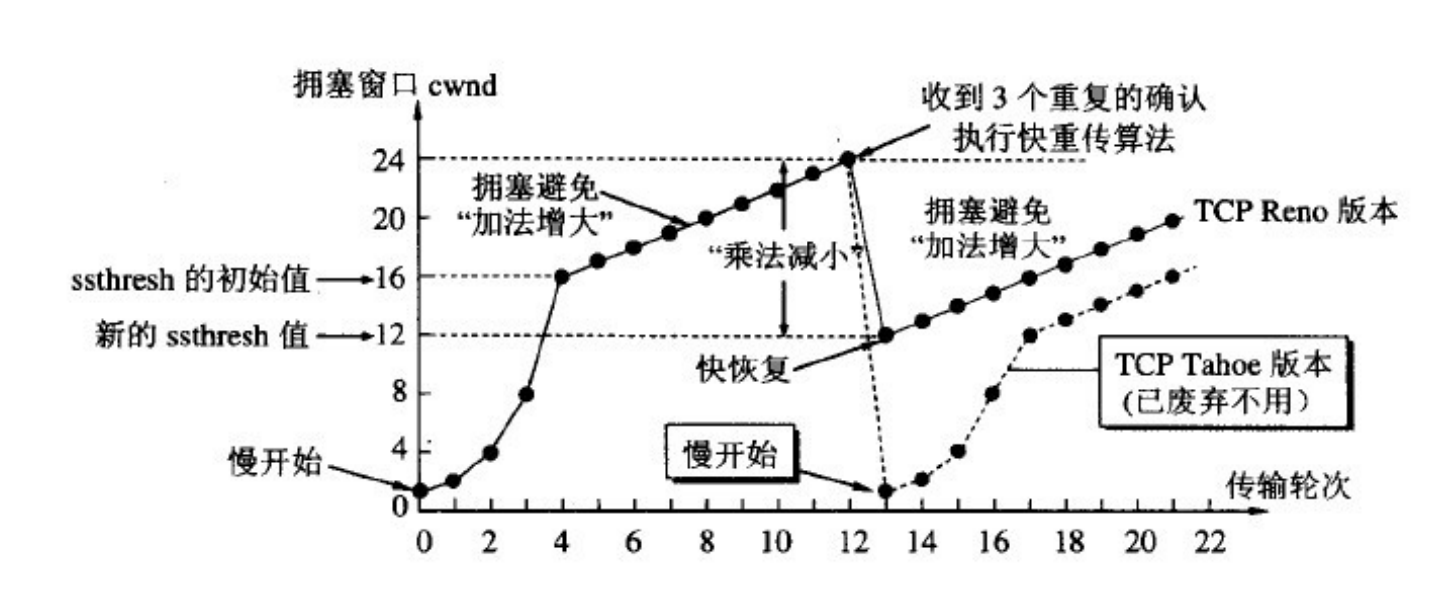
(3)快速重传
- 快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)。发送方只要连续收到三个重复确认就立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。
- 由于不需要等待设置的重传计时器到期,能尽早重传未被确认的报文段,能提高整个网络的吞吐量
(4)快速恢复
- 当发送方连续收到三个重复确认时,就执行“乘法减小”(指数减小)算法,把ssthresh门限减半。但是接下去并不执行慢开始算法。
- 考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法。
OSI各层具体应用
状态码3XX (Redirection 重定向状态码)
3XX 响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。
(1)301 Moved Permanently
永久重定向。
该状态码表示请求的资源已经被分配了新的 URI,以后应使用资源指定的 URI。新的 URI 会在 HTTP 响应头中的 Location 首部字段指定。若用户已经把原来的URI保存为书签,此时会按照 Location 中新的URI重新保存该书签。同时,搜索引擎在抓取新内容的同时也将旧的网址替换为重定向之后的网址。
使用场景:
- 当我们想换个域名,旧的域名不再使用时,用户访问旧域名时用301就重定向到新的域名。其实也是告诉搜索引擎收录的域名需要对新的域名进行收录。
- 在搜索引擎的搜索结果中出现了不带www的域名,而带www的域名却没有收录,这个时候可以用301重定向来告诉搜索引擎我们目标的域名是哪一个。
(2)302 Found
临时重定向。
该状态码表示请求的资源被分配到了新的 URI,希望用户(本次)能使用新的 URI 访问资源。和 301 Moved Permanently 状态码相似,但是 302 代表的资源不是被永久重定向,只是临时性质的。也就是说已移动的资源对应的 URI 将来还有可能发生改变。若用户把 URI 保存成书签,但不会像 301 状态码出现时那样去更新书签,而是仍旧保留返回 302 状态码的页面对应的 URI。同时,搜索引擎会抓取新的内容而保留旧的网址。因为服务器返回302代码,搜索引擎认为新的网址只是暂时的。
使用场景:
- 当我们在做活动时,登录到首页自动重定向,进入活动页面。
- 未登陆的用户访问用户中心重定向到登录页面。
- 访问404页面重新定向到首页。
(3)303 See Other
该状态码表示由于请求对应的资源存在着另一个 URI,应使用 GET 方法定向获取请求的资源。
303 状态码和 302 Found 状态码有着相似的功能,但是 303 状态码明确表示客户端应当采用 GET 方法获取资源。
303 状态码通常作为 PUT 或 POST 操作的返回结果,它表示重定向链接指向的不是新上传的资源,而是另外一个页面,比如消息确认页面或上传进度页面。而请求重定向页面的方法要总是使用 GET。
注意:
- 当 301、302、303 响应状态码返回时,几乎所有的浏览器都会把 POST 改成GET,并删除请求报文内的主体,之后请求会再次自动发送。
- 301、302 标准是禁止将 POST 方法变成 GET方法的,但实际大家都会这么做。
(4)304 Not Modified
浏览器缓存相关。
该状态码表示客户端发送附带条件的请求时,服务器端允许请求访问资源,但未满足条件的情况。304 状态码返回时,不包含任何响应的主体部分。304 虽然被划分在 3XX 类别中,但是和重定向没有关系。
带条件的请求(Http 条件请求):使用 Get方法 请求,请求报文中包含(if-match、if-none-match、if-modified-since、if-unmodified-since、if-range)中任意首部。
状态码304并不是一种错误,而是告诉客户端有缓存,直接使用缓存中的数据。返回页面的只有头部信息,是没有内容部分的,这样在一定程度上提高了网页的性能。
(5)307 Temporary Redirect
307表示临时重定向。该状态码与 302 Found 有着相同含义,尽管 302 标准禁止 POST 变成 GET,但是实际使用时还是这样做了。
307 会遵守浏览器标准,不会从 POST 变成 GET。但是对于处理请求的行为时,不同浏览器还是会出现不同的情况。规范要求浏览器继续向 Location 的地址 POST 内容。规范要求浏览器继续向 Location 的地址 POST 内容。
VUE
https://www.yuque.com/ayong-cbshf/bnd60u/zaibr2?inner=VUE
路由两种模式及区别
P153
https://blog.csdn.net/qq_18599727/article/details/124462666
https://mp.weixin.qq.com/s/BDS9ule4OGUHiH2RaWtVVQ
VUE2.0和VUE3.0的区别
P143
路由懒加载的原理是什么?
通过Webpack编译打包后,会把每个路由组件的代码分割成一一个js文件,初始化时不会加载这些js文件,只当激活路由组件才会去加载对应的js文件。
作用就是webpack在打包的时候,对异步引入的库代码进行代码分割时(需要配置webpack的SplitChunkPlugin插件),为分割后的代码块取得名字
Vue中运用import的懒加载语句以及webpack的魔法注释,在项目进行webpack打包的时候,对不同模块进行代码分割,在首屏加载时,用到哪个模块再加载哪个模块,实现懒加载进行页面的优化。
VUEX
VUEX中的subscribe API
App.vue
this.$store.commit('add')
1
store.js
3
const store = new Vuex.Store({
state:{
name:'xxx',
age:20
},
mutations:{
add(state){
console.log(state.age);
}
}
})
store.subscribe((mutation,state) => {
console.log(mutation.type)
console.log(state)
})
/*
20
add
{ name : 'xxx', age : 20}
*/
路由参数丢失
场景:有三个页面(a-列表页面,b-内页1,c-内页2),页面a->页面b->页面c有参数传递.从a进入b后,刷新b页面拿不到a页面传进来的参数.或者b页面再进入c页面,并由c页面返回b页面,b页面丢失a页面传入的参数.
参数的传递使用的是vue-router, query传参
let para = {
id: info.subjId,
subjInit: info.subjInit,
subjectGuid: info.subjectGuid,
visitNo: info.visitNo
}
this.$router.push({path:'/sign_in_already_detail',query:{para: para }})
首先说明一下,使用路由的query传参是可以在刷新的时候保留参数的
之所以出现上面的问题是因为:在query传参数的时候没有对对象参数序列化–就是没有转成字符串.
所以b页面(接收参数的页面)的路由展示是下图这样. 只有在第一次进入b页面的时候能够拿到参数,之后就获取不到了。
this.$router.push({path:'/sign_in_already_detail',query:{para: JSON.stringify( para) }})
这样进入b页面的路由就是如下图这样的,即使在刷新页面后地址也是不会变的.
原文链接:https://blog.csdn.net/weixin_33595317/article/details/112899433
附录笔记
核心:有自己思考
准备一两个技术场景,详细展开
- 面试官大多数问你实现了什么,怎实现?从这里开始发挥
- 模板——有几种实现方式,我选了哪一种,为什么选这一种?
- 问的最多就是业务
实习期间的框架和资源的 loader 看一下
表单提交,路由信息丢失
url 特殊字符编码
首屏闪进
父子组件生命周期问题
源码阅读:vuex刷新页面丢失问题:使用 vuex subscribe方法——源码实现也使用localstorage
1.为什么有localstorage 还要搞个vuex? 2.数据放在localstorage,用户通过控制台就可以看到数据了,怎么解决?3.localstorage里面的数据,人为修改后,刷新页面,修改后的值就赋给vuex了,这个怎么解决?
发布订阅模式

附件简历:
个人信息
- 性别:男 年龄:21
- 求职意向:Web前端开发工程师
- 掌握技能:
- 掌握 HTML5+CSS3页面布局,熟练使用flex布局、rem布局、less预编译与媒体查询实现移动端布局,并结合W3C标准,精准还原设计稿。
- 掌握原生 JavaScript 以及ES6新特性,熟悉使用axios与promise进行前后端交互,对于JS事件循环,垃圾回收机制,函数柯里化,闭包,以及V8引擎原理有一定了解。
- 掌握 vue2.0 (vuex,vue-router,vue-cli)了解 vue3.0 、原生微信小程序等前端框架。
- 掌握 HTTP及计算机网络相关协议;了解 node.js、webpack、Git 等前端架构技术。
- 掌握 Element-UI、Ant Design、Vant 等常用UI 组件库,以及常用的PhotoshopMasterGo切图工具。
- 了解Python、Java、PHP等后端开发语言,Python在机器学习,数据建模方面有所实践。
教育经历
- 全日制本科——天津商业大学——信息工程学院——专业:电子商务——2019.9~2023.7
- 主修课程:数据结构、数据库、计算机网络、操作系统基础、软件工程
- 综合绩点:4.26,年级前 7%
- 通过 CET4 英语等级考试
校园经历
- 2022年 发表一篇SCI二区文章*C4 Olefin production conditions Optimizing based on a hybrid GXGB-SSA Model*
- 2022年 全国市场调研大赛”正大杯”国家级二等奖 ——负责数据建模与代码实现
- 2021年 全国大学生数学建模竞赛天津市一等奖 ——负责数据建模与代码实现
- 2021年 天津市“启程杯”人工智能鼠竞赛二等奖 ——组长,负责智能鼠软硬件调试
- 2021年 大学生创新创业训练计划项目天津市市级立项
- 2021年 获得天津商业大学信息工程学院“卓越青年”称号
- 曾获得天津商业大学校级三好学生、优秀干部
- 曾获国家励志奖学金、天津商业大学二等奖学金两次
- 曾任班级学习委员、现任团支书
实习经历
联想云,Filez-zbox产研部,web前端开发实习生,2022.06~2022.10
- 使用多种项目管理工具进行多端协作开发(gtilab、jira、fork),参与TDD模式开发。
- 日常修复多端BUG,与产品、交互、后端协调确定最佳解决方案。参与日常技术分享会。
- 参与新需求“930”和“精卫计划”需求评审、概要设计、详细设计、代码编写、测试联调。
- 通过使用 vue 路由守卫处理鉴权,修复首页闪进闪退bug。
- 通过 encodeURIComponent 方法对URL编码,修复文件夹路径包含特殊字符无法访问的bug。
- 通过 localStorage 与subscribeAPI对VUX做数据持久化,修复页面刷新参数丢失bug。
- 通过运用父子组件生命周期钩子交替顺序,解决异步请求结果获取不到的问题。
北京凌波创元科技有限公司,研发部门,前端开发实习生,2021.07~2021.09
- 参与北京林业大学园林学院官网制作,根据设计稿使用原生HTML、CSS、JS精准还原页面布局。
- 使用 Swiper 插件制作首页轮播图。
- 参与友邦保险报表技术迁移,使用ActiveReportJS制作,使用Git进行多人协作开发。
项目经历
天津商业大学信息工程学院智慧党建系统 2022.01 ~ 至今使用技术vue、vue-cli、vue-router、Element-ui、axios、VUEX、JS以及其他第三方插件与学院党建办公室合作开发预上线党建系统,包括库表查询、文件审核、分配谈话人、上传导出文件等功能。
- 前端技术组长,组织项目需求分析、系统概要设计、详细设计、确定技术选型以及组织人员分工
- 使用 Token 技术实现单点登录认证,防范CSRF(跨站请求伪造)攻击。
- 使用localStorage、VUEX对用户登录信息Token进行管理。
- 使用 vue-router 管理页面路由,并通过路由懒加载进行首屏优化,提升交互体验。
- 通过 vue-virtual-scroller 插件进行长列表渲染优化,有效提高网页加载速度。
- 通过封装防抖、节流函数进行搜索框关联以及图片懒加载性能优化。
- 使用 JSONbig 插件解决JS中大数字的问题。
- 通过 prerender-spa-plugin 插件进行预渲染,有效提高网站SEO。
仿头条后台管理项目 2021.12 ~ 2022.03使用技术vue、vue-cli、vue-router、Element-ui、axios、VUEX、JS、jszip、FileSaver、以及其他第三方插件本项目基本功能模块分为内容管理、素材管理、评论管理、文章发布、个人中心。涉及技术包括:
- 封装 axios 向后端发送请求,使用请求拦截器、响应拦截器对请求和数据进行处理。
- 使用ElementUI对页面进行快速搭建,实现页面组件的封装与重用。
- 使用全局事件总线处理公共数据,进行组件间通信。
- 使用文件上传技术处理文件并进行压缩,提高文件上传效率。
- 使用 tiptap 插件实现富文本编辑器,使用 vue-cropper 插件实现头像裁切功能。
- 使用docxtemplater、jszip、FileSaver等技术实现excel、word的下载与导出。
仿喜马拉雅微信小程序 2021.12 ~ 2022.01使用技术原生微信小程序、promise、wxs、commonjs、组件封装与复用 本项目主要是用原生微信小程序进行开发包括首页、节目详情页、收藏页。
- 使用promise封装wx.request请求,数据来源于后端api。
- 使用commonjs进行项目模块化,封装公共方法。
- 使用wxs写外部方法导入到wxml文件中进行精度处理。
- 使用组件封装,将公用组件抽象成独立模块,便于组件复用。
- 使用globalData全局变量进行公共状态管理,实现收藏添加与取消功能。
- 使用navigate进行url传参,实现组件实现页面与页面数据之间传递



